
TOC
- 聊聊你了解的W3C规范?
- DOM树怎么生成的?
- script标签中
async和defer属性的区别? - 讲下浏览器渲染时的合成层?
- 回流和重绘的区别?
- 关于客户端存储?
- 什么是
process-per-site-instance策略? - 能说在什么是核心网页指标Core Web Vitals吗?
- JSBridge实现原理?
- 如何解决首页加载慢的问题?
- 关键渲染路径是啥?如何优化?
- 如何优化TTFB?
- 如何测量性能?
- 懒加载有哪些手段?
- 普通
<script>与<script type="module">有哪些区别? - HTML属性
rel="preload"、rel="preloadmodule"、rel="prefetch"、rel="prerender"、rel="subresources"等有何区别?
- 谈谈你对MVVM的理解?
- Vue的响应式系统如何创建的?
- Vue为何跟推荐使用模板而非渲染函数?
- Vue3组合式API的优势有哪些?
- Vue3的渲染机制?
- Vue的生命周期?
- Vue2和Vue3 Diff算法分别说一下?
- 解释一下 vue-router 的完整的导航解析流程是什么?
- Vue内置组件
KeepAlive实现原理? - Vue内置组件
Teleport实现原理? - Vue内置组件
Transition实现原理? - Vue3如何实现一个防抖的Ref?
- 为何不建议v-if与v-for一起使用?
- Vue3特性开关怎么实现的?
- Vue3错误处理如何实现的?
- Vue如何给数组建立响应性?
- Vue如何代理Set(WeakSet)和Map(WeakMap)?
- Vue如何处理响应丢失的问题?
- Vue如何实现自动脱ref?
- Vue2双端Diff原理?
- Vue3快速Diff原理?
- 如何实现异步组件?
- Webpack loader和plugin的区别?
- Webpack中module、chunk、bundle、vendor区别是啥?
- Webpack中魔法注释webpackPrefetch和webpackPreload有啥区别?
- Webpack生命周期有哪些?
- Webpack优化手段有哪些?
- Webpack如何实现热更新?
- Webpack的运行时如何实现?
- Webpack的tree shaking为何不太行?
- Vite为啥比Webpack快?
- Webpack和Vite的区别?
- 如何做性能优化的?
- 如何理解依赖预打包?
- 如何理解Vite的依赖预构建?
- 什么是幽灵依赖?👻
- Rollup如何实现的?
- 如何实现个简单的Bundler?
- 一个基础的Bundler需要包含哪些内容?
浏览器
聊聊你了解的W3C规范?
W3C相关规范工作组组成:
- CSS 工作组
- HTML ⼯作组(HTMLWG) 与WHATWG合作发布HTML与DOM正式推荐标准
- ⽆障碍指南⼯作组发布了WCAG 3.0 ⼯作草案(WD),除继承WCAG 2.2及以前版本(2.1、2.0)之外,还⾸次纳⼊ UAAG 2.0 (⽤户代理⽆障碍指南) 和ATAG 2.0 (创作⼯具⽆障碍指南) 的内容并进⾏扩展。将提供⼀个新模式来更全 ⾯和灵活地解决 Web ⽆障碍(可访问性)问题
- Web 性能⼯作组继续发布性能监测与优化相关的 API
- Web 应⽤⼯作组持续客户端应⽤相关技术讨论,Web 在线编辑相关的技术,如⾼亮选择、虚拟键盘、内 容选择等
- WPT Web平台测试 规范特性的测试平台
对HTML来说一直都有两个组织维护:HTML工作组(HTMLWG)与WHATWG。是两个独立的组织,不过随着后期的发展,有关于HTML相关的标准都由WHATWG组织维护和推进。
以前描述CSS都是使用版本号来描述,比如CSS1.0、CSS2.0、CSS2.1和CSS3之类, 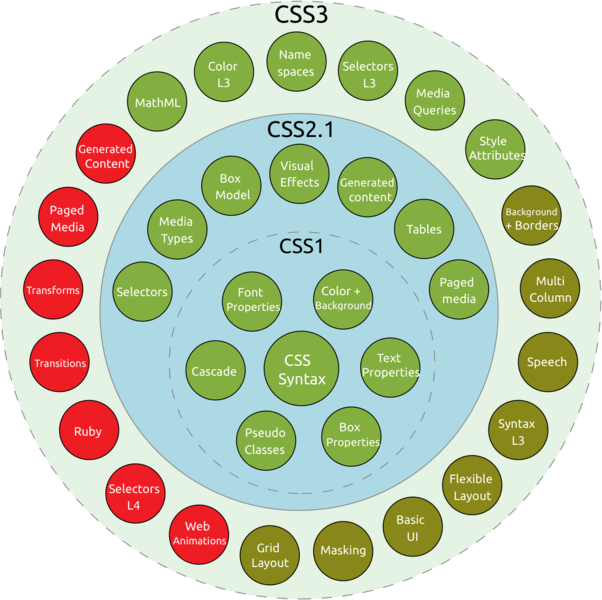 但随着CSS功能模块变多、每个功能模块发展进度有差异,后面定义CSS规范不再以整体版本号描述,而是按单个模块版本维护,如CSS Grid模块,分为Level1、Level2、Level3之类。
但随着CSS功能模块变多、每个功能模块发展进度有差异,后面定义CSS规范不再以整体版本号描述,而是按单个模块版本维护,如CSS Grid模块,分为Level1、Level2、Level3之类。
WCAG相关规范构建了具有可访问性Web应用的理论参考和依据。UAAG 2.0 (⽤户代理⽆障碍指南) 和ATAG 2.0 (创作⼯具⽆障碍指南)
Weixin Official Accounts Platform
DOM树怎么生成的?
一旦浏览器收到第一块数据,它就开始解析收到的信息。“解析”是浏览器将通过网络接收到的数据转换为DOM、CSSOM的步骤,通过渲染器把DOM和CSSOM在屏幕上绘制成页面。
渲染DOM树分为5个阶段:
- 处理HTML标记并构造DOM树。当遇到CSS文件、非阻塞资源(如图片)时解析继续进行,但对于没有
defer或async属性的<script>标签时,浏览器会阻塞渲染并停止HTML的解析(虽然浏览器的预加载扫描器会加速该过程)。等待获取CSS不会阻塞HTML解析但会阻塞JavaScript! - 处理CSS并构建CSSOM树。CSSOM包含来自用户代理样式表的样式。在此同时,也会有JavaScript编译、构建辅助功能树等过程
- 将DOM和CSSOM组合为一个Render树。Render树将所有相关样式匹配到DOM树的每个可见节点,并根据CSS级联确定每个节点的计算样式。
- 在渲染树上运行布局以计算每个节点的几何体。第一次确定节点的大小和位置称为布局,随后对节点和大小的重新计算称为回流。
- 最后一步将各个节点绘制到屏幕上。绘制可以将布局树上的元素分解为多层,将内容提升到GPU上的层可以提高绘制和重绘性能。当文档中各个不同部分以不同的层绘制相互重叠时,就必须进行合成,以确保按照正确的顺序绘制到屏幕上。
script标签中async和defer属性的区别?
带async属性的脚本:
- 对于普通脚本则会并行请求,并加快解析和执行;
- 对于模块脚本,那么脚本及其所有依赖都会在延迟队列中执行,确保它们会被并行请求并尽快解析和执行。
带defer属性的脚本:
- 对模块脚本不生效(默认
defer) - 对缺少
src属性的脚本不生效 - 表示在文档解析后,但在触发
DOMContentLoaded之前执行 - 阻塞
DOMContentLoaded事件触发,直到脚本完成加载并执行 - 按照文档出现顺序执行
讲下浏览器渲染时的合成层?
在每个DOM树节点都会对应一个LayoutObject,当它们的LayoutObject处于相同的坐标空间时,就会形成一个RenderLayers,也就是渲染层。
RenderLayers保证页面以正确的顺序合成,这时候就出现了层的合成(composite),从而正确处理透明元素与重叠元素的显示。
在Chrome中有两种不同的层类型:
- RenderLayer渲染层,负责对应的DOM子树
- GraphicsLayer图形层,负责对应的RenderLayer子树
在RenderLayer下有RenderObject,其保持了树结构并通过向绘图上下文(GraphicsContext)发出绘制调用来绘制Nodes。 每个GraphicsLayer下都有一个GraphicsContext,其用于负责输出该层的位图,位图储存在共享内存中作为纹理上传到GPU中,最后由GPU将多个位图合成,然后draw到屏幕上
某些特殊的渲染层会被认为是合成层(Composition Layer),合成层拥有单独的GraphicsContext,而其他非合成层的渲染层,则和第一个拥有GraphicsContext父层共用一个。
影响composite的因素:
- Transform 3D:translate3D,translateZ等
- video、canvas、iframe等元素
- 通过
Element.animate实现的opacity动画转换 - 通过CSS 动画实现的opacity动画转换
- postion: fixed;
- will-change
- filter
- 有合成层的后代元素同时本身overflow不为visible
- …
回流和重绘的区别?
- Reflow(回流):浏览器要花时间去渲染,当它发现了某个部分发生了变化影响了布局,那就需要倒回去重新渲染。
- Repaint(重绘):如果只是改变了某个元素的背景颜色,文字颜色等,不影响元素周围或内部布局的属性,将只会引起浏览器的repaint,重画某一部分。
关于客户端存储?
传统方式:
- cookies
新流派:
- Web Storage API
- IndexedDB API
未来:
- Cache API:用于存储特定HTTP请求的响应文件,通常与Service Worker一起使用。
关于Web Storage API:
- sessionStorage只在页面会话期间生效(浏览器打开状态,包含页面加载和恢复);localStorage始终存在
- sessionStorage为每个给定的源维持一个独立的存储区域(同一URL多个Tab,Storage是独立的),如果新标签或窗口打开新页面会复制顶级浏览器会话上下文(共享Storage)
- Storage特定于页面协议,区分https、http
- StorageEvent:Storage对象发生变化,
storage事件会触发:相同域名下的其他页面发生的变化才会触发
什么是process-per-site-instance策略?
每个标签对应一个渲染进程,如果从一个页面打开了一个新页面,新打开的页面与当前页面还属于同一个站点的话,那么新页面会复用当前页面的渲染进程。
能说在什么是核心网页指标Core Web Vitals吗?
JSBridge实现原理?
JSBridge是一种webview侧和native侧进行通信的手段。webview通过JSBridge调用Native的能力,Native通过JSBridge在Webview端执行一些逻辑。
- API注入,原理其实就是 Native 获取 JavaScript环境上下文,并直接在上面挂载对象或者方法,使 js 可以直接调用,Android 与 IOS 分别拥有对应的挂载方式
- WebView 中的 prompt/console/alert 拦截,通常使用 prompt,因为这个方法在前端中使用频率低,比较不会出现冲突
- WebView URL Scheme 跳转拦截(JSBridge原理解析)
如何解决首页加载慢的问题?
等待资源加载时间和大部分情况下的浏览器单线程执行是影响 Web 性能的两大主要原因。了解浏览器单线程的本质与最小化主线程的责任可以优化 Web 性能,来确保渲染的流畅和交互响应的及时。
导致加载慢可能的因素:
- 网络延时
- 资源文件体积过大
- 资源加载重复发送请求
- 加载脚本,渲染内容卡住了
解决方案:
- 减少入口文件体积(路由懒加载)
- 静态资源本地缓存(service worker、http缓存)
- UI框架按需加载(babel-plugin-import)
- 图片资源压缩(在线字体图标、雪碧图)
- 开启Brotli/Gzip压缩
- 使用SSR
推荐的优化启动性能的方案:
- 异步执行的脚本标签上加async或defer
- 需要解码的资源文件(解码JPEG转为原始纹理数据),最好在worker中做
- 所有能并行的数据处理都应该并行化
- 在启动的HTML文件中,不包含不会在关键渲染路径中出现的样式和脚本,最好仅在需要时加载
- 不要让Web引擎构建不需要的DOM
关键渲染路径是啥?如何优化?
关键渲染路径是浏览器将 HTML,CSS 和 JavaScript 转换为屏幕上的像素所经历的步骤序列。优化关键渲染路径可提高渲染性能。关键渲染路径包含了 文档对象模型(DOM),CSS 对象模型 (CSSOM),渲染树和布局。
压缩和媒体查询来异步处理CSS为非阻塞请求。
- 通过异步、延迟加载或者消除非关键资源来减少请求数量
- 优化必须的请求数量和每个文件体积
- 区分关键资源优先级来优化被加载资源的顺序,缩短关键路径长度
如何优化TTFB?
Time to First Byte(TTFB)是一项基本Web性能指标,作为粗略指南,网站应努力达到0.8s或更短。 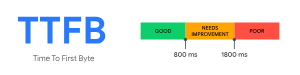
以下内容来自Optimize Time to First Byte
- 特定平台优化指导
- 选择好的托管服务
- 确保足够的内存
- 确保托管平台的后端堆栈技术较新
- 使用CDN 将资源缓存在离用户物理距离更近的边缘服务器上。CDN其他优势如下:
- 更快的DNS解析速度
- CDN可能使用HTTP2/3等现代协议从边缘服务提供内容
- HTTP/3适用UDP解决了TCP队头阻塞等问题
- CDN可能还提供现代版本的TLS,可降低TLS协商中的延迟 TLS1.3的设计尤其旨在使TLS协商尽可能短
- 一些CDN提供商提供通常被称为边缘工作线程的功能,该功能使用与Service Worker类似的API拦截请求,以编程方式管理边缘缓存中的响应或完全重写响应
- CDN服务商擅长压缩优化
- CDN服务商自动缓存静态资源的压缩响应
- 尽可能缓存内容
- 避免多个页面重定向 重定向类型分为:
- 同源重定向。完全发生在你的网站
- 跨源重定向。例如短链服务
- 流式传输HTML 浏览器经过优化,可在流式传输时有效的处理标记
- 使用Service Worker 是用Service Worker充当浏览器和服务器之间的代理
- 使用
103 Early Hints信息状态响应码,一般和Linkheader一起使用,来允许用户在浏览器还在准备响应数据的时候预加载一些资源
如何测量性能?
性能API:Performance API - Web API 接口参考 | MDN
工具和指标:
- PageSpeed Insights
- WebPageTest - Website Performance and Optimization Test
- Devtools的网络监视器和性能监视器
- Chrome的Lighthouse
懒加载有哪些手段?
- 代码拆分
- 入口点分离,通过应用的入口点分离代码
- 动态分离:使用动态
import()语句分离代码
- 脚本类型模块 任何
<script type="module">模块脚本标签默认情况下都会延迟(defer) - CSS可使用媒体类型和查询实现非阻塞渲染 如:
<link href="style.css" rel="stylesheet" media="all" /> - 字体。默认情况下字体会延迟到构造渲染树之前,这可能会导致文本渲染延迟 可使用
<link rel="preload">、font-display、字体加载API覆盖默认行为并预加载字体资源 - 图片和iframe,可加
loading="lazy"属性(延迟加载屏幕外的图片/iframe)
普通<script>与<script type="module">有哪些区别?
- 模块代码需要使用CORS协议跨源获取
- 默认自动延迟加载(defer)
- 默认使用严格模式
- 使用范围仅限该模块(无法全局获得)
HTML属性rel="preload"、rel="preloadmodule"、rel="prefetch"、rel="prerender"、rel="subresources"等有何区别?
rel="preload",提前下载并缓存资源,常用于字体文件、媒体文件等比较大的资源,提前下载并缓存,防止阻塞主渲染进程rel="preloadmodule",提前下载、解析、编译模块文件,仅对<script type="module">生效,常用于模块依赖项的预加载rel="prefetch",提前获取下一导航页面的资源(优先级比preload低),但对当前页面资源无效。rel="prerender",在背后提前渲染指定的页面,如果用户导航到该页面可加速rel="subresources",与preload相同但无法获取资源优先级
NodeJS
如何做NodeJS性能优化?
- 不要过度优化。
- 确定慢的类型和种类。CPU密集型、IO密集型,还是内存使用过高?
- 优化代码
- CPU密集型:优化算法、优化方案、基于Worker实现多线程、换原生语言实现
- IO密集型:利用Node的异步特性,减少阻塞,使用流处理大文件
- 增加缓存
- 注意程序外的优化。(换硬件、更新版本)
- 其他有效的点
- 打包依赖
- 按需加载
- require(“v8-compile-cache”)
- 增加benchmark库或CI Action。
How we made Vite 4.3 faaaaster 🚀 | sun0day’s blog - lost in code
npm install 和 npm ci有啥区别?
npm ci 和 npm install 类似,区别是 npm ci 要求项目中必须有 package-lock.json,同时他会完全根据 lock 文件进行依赖安装,如果和 package.json 中的文件有冲突,会报错。同时顾名思义,npm ci 是在 ci 环境中推荐使用的 npm install。
HTTP
如何理解CDN?
CDN(Content Delivery Network)内容分发网络
构建在现有网络基础之上的智能虚拟网络,依靠部署在各地的边缘服务器,通过中心平台的负载均衡、内容分发、调度等功能模块,使用户就近获取所需内容,降低网络拥塞,提高用户访问响应速度和命中率。
CDN 的关键技术主要有内容存储和分发技术。
用户在上网的时候不用直接访问源站,而是访问离他“最近的”一个 CDN 节点,术语叫边缘节点,其实就是缓存了源站内容的代理服务器。
原理:
- DNS返回的不再是IP地址,而是CNAME别名记录,指向CDN的全局负载均衡 CNAME实际上在域名解析中充当中间人(代理)角色,
- 由于没有IP地址,本地DNS会向负载均衡系统发请求进行智能调度
- 看用户IP地址,查表得知地理位置,找相对最近的边缘节点
- 看用户所在运营商,找相同网络的边缘节点
- 检查边缘节点的负载状况,找负载较轻的节点(其他如:健康状况、服务能力、带宽、响应时间等)
- 得到最合适的边缘节点后,把该节点返回给用户
好处:
- 更快的DNS解析
- CDN服务商可能使用更现代的HTTP协议
- TLS协商过程可能更快(版本高)、使用HTTP的QUIC
- 工作线程队列功能提供类似service worker的缓存响应与编程能力
- 压缩优化、自动静态资源响应压缩
DNS解析流程?
DNS相当于翻译官,将域名翻译为IP地址。
- 首先找浏览器的DNS缓存
- 没找到则找操作系统DNS缓存
- 还没找到则本地域名服务器
- 还没有,则:
- 向根DNS服务器获取顶级DNS服务器地址
- 向顶级DNS服务器地址获取权威DNS服务器地址
- 最终得到IP
- 本地域名服务器给到操作系统,自己缓存下
- 操作系统给到浏览器,自己缓存下
- 浏览器得到,自己缓存下
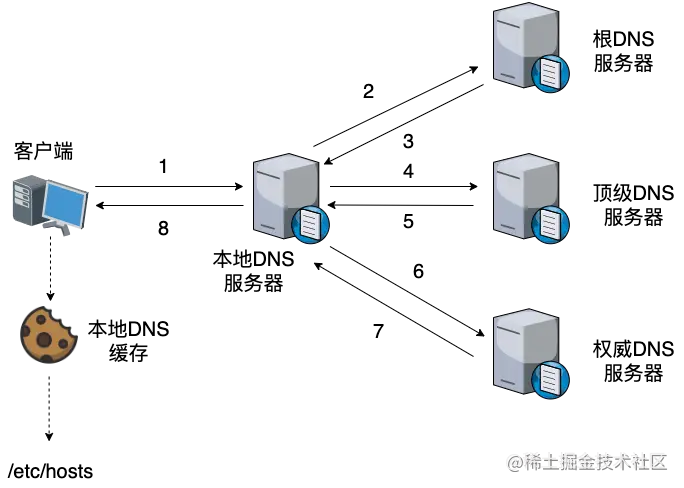
- 根 DNS 服务器:返回顶级域 DNS 服务器的 IP 地址
- 顶级 DNS 服务器:返回权威 DNS 服务器的 IP 地址
- 权威 DNS 服务器:返回相应主机的 IP 地址
HTTP2.0有哪些优化?HTTP3了解吗?
- HTTP/2 是二进制协议而不是文本协议。不再可读,也不可无障碍的手动创建,改善的优化技术现在可被实施。
- 这是一个多路复用协议。并行的请求能在同一个链接中处理,移除了 HTTP/1.x 中顺序和阻塞的约束。
- 压缩了标头。因为标头在一系列请求中常常是相似的,其移除了重复和传输重复数据的成本。
- 其允许服务器在客户端缓存中填充数据,通过一个叫服务器推送的机制来提前请求。
HTTP 的发展 - HTTP | MDN HTTP传输层变为QUIC而不是TCP。 HTTP2通过单个TCP连接运行,所以在TCP层处理的数据丢失检测和重传会阻止所有流得传输。 QUIC通过UDP运行多个流并为每个流实现了丢失检测和重传。
HTTPS 与HTTP的区别?
- HTTPS是HTTP协议的安全版本,HTTP协议的数据传输是明文的,是不安全的,HTTPS使用了SSL/TLS协议进行了加密处理,相对更安全
- HTTP 和 HTTPS 使用连接方式不同,默认端口也不一样,HTTP是80,HTTPS是443
- HTTPS 由于需要设计加密以及多次握手,性能方面不如 HTTP
- HTTPS需要SSL,SSL 证书需要钱,功能越强大的证书费用越高
HTTPS如何保证安全?
在采用SSL后,HTTP就拥有了HTTPS的加密、证书和完整性保护这些功能
SSL(Secure Sockets Layer 安全套接字协议),及其继任者传输层安全(Transport Layer Security,TLS)是为网络通信提供安全及数据完整性的一种安全协议
- 对称加密:采用协商的密钥对数据加密
- 非对称加密:实现身份认证和密钥协商
- 摘要算法:验证信息的完整性
- 数字签名:身份验证
为什么说HTTPS比HTTP安全? HTTPS是如何保证安全的?
HTTP缓存?
缓存分为4种,当一次查找且都没命中时,才会请求网络:
- Service Worker + Cache Storage
- Memory Cache。内存使用率比较高的文件。关闭Tab页面就释放
- Disk Cache。 比较大的 JS、CSS 文件会直接被丢进磁盘。
- Push Cache + HTTP2。只在会话存在
通过HTTP Header设置缓存策略:
- 强缓存 使用强缓存不会发送HTTP请求,直接从缓存中拿数据,状态码为200,size显示为
from disk cache或from memory cache。 强缓存可以通过设置两种 HTTP Header 实现:Expires(服务器事件和浏览器事件可能不一致)和Cache-Control。 - 协商缓存。 强缓存失效就进入协商缓存。 浏览器在请求头中携带缓存标识,服务器根据缓存标识决定是否使用缓存,协商缓存生效则返回 304 和 Not Modified,失效则返回 200 和最新版本请求结果。 协商缓存可以可以通过设置两种 HTTP Header 实现:
Last-Modified和ETag。
强制重新验证:
cache-control设置为no-cache或者cache-control设置为max-age=0, must-revalidate,这是HTTP1.1之前的兼容方案- 同时设置
ETag和Last-Modified
不使用缓存:cache-control设置为no-store
Cache-Control中no-cache和no-store有何区别?
no-cache:在发布缓存副本之前,强制要求缓存把请求提交给原始服务器进行验证 (强制协商缓存验证)。no-store:缓存不应存储有关客户端请求或服务器响应的任何内容,即不使用任何缓存(完全不缓存)。
CSRF是啥?如何防范?
Cross-Site Request Forgery
跨站请求攻击,简单地说,是攻击者通过一些技术手段欺骗用户的浏览器去访问一个自己曾经认证过的网站并执行一些操作(如发邮件,发消息,甚至财产操作如转账和购买商品)。由于浏览器曾经认证过,所以被访问的网站会认为是真正的用户操作而去执行。这利用了web中用户身份验证的一个漏洞:简单的身份验证只能保证请求是发自某个用户的浏览器,却不能保证请求本身是用户自愿发出的。
Cross-Site Request Forgery Prevention - OWASP Cheat Sheet Series 如何防范:
- 后端框架一般带内置实现
- 使用令牌同步模式 当用户发送请求时,服务器端应用将令牌嵌入HTML表单,并发送给客户端。客户端提交HTML表单时候,会将令牌发送到服务端,令牌的验证是由服务端实行的。令牌可以通过任何方式生成,只要确保随机性和唯一性
- 检查Referer字段 这个字段用以标明请求来源于哪个地址。在处理敏感数据请求时,通常来说,Referer字段应和请求的地址位于同一域名下。
- 静态网站使用double submit cookie技术 服务端生成个随机数给客户端,请求时带上给服务端验证。
XSS是啥?如何防范?
跨站脚本(英语:Cross-site scripting,通常简称为:XSS)是一种网站应用程序的安全漏洞攻击,是代码注入的一种。它允许恶意用户将代码注入到网页上,其他用户在观看网页时就会受到影响。这类攻击通常包含了HTML以及用户端脚本语言。
XSS攻击通常指的是通过利用网页开发时留下的漏洞,通过巧妙的方法注入恶意指令代码到网页,使用户加载并执行攻击者恶意制造的网页程序。
如何防范:
- 过滤特殊字符(DOMPurify、HTML Sanitizer)
- 关闭JavaScript(浏览器设置)
cookie有何作用?如何禁止访问?
作用:
- 会话状态管理。如用户登录状态、购物车、游戏分数或其他需要记录的信息
- 个性化设置。如用户自定义设置、主题或其他设置
- 浏览器行为追踪。如跟踪分析用户行为等。
限制:
- 大小不能超过4kb
- cookie总数不能超过20+,具体取决于浏览器
- 每次请求都会携带cookie数据,会带来额外的性能开销
如何限制访问Cookies:
- Secure。只应被HTTPS协议加密过的请求发送给服务端(但无法阻止cookie中敏感信息的访问)
- HttpOnly。无法通过
Document.cookieAPI访问到带HttpOnly属性的cookie
三方cookie:非当前域下的cookie都属于三方cookie
三方cookie的使用场景:
- 单点登陆
- 前端日志打点
- 广告营销
- 记录用户画像
SameSite干啥的?阻止浏览器将此Cookie与跨站点请求一起发送,降低跨源信息泄漏的风险。
能介绍下HTTP 访问控制(CORS)吗?
跨域访问:双方同意的基础上实现数据的可编程访问
- 为啥会产生跨域?
- 保护登录鉴权数据
- 那些不会产生跨域?
- 如何跨域
- 带域名限制的跨域方案
- iframe + postMessage 允许不同页面发送消息
- CORS白名单跨域 一组W3C标准的名称,主要使用服务端的header来控制是否能发送请求
- access-control-allow-origin 决定来访域名
- access-control-allow-headers 决定支持哪些header
- Access-Control-Allow-Credentials 决定是否带本域名的cookie
- WebSocket 不属于http协议,不存在跨域
- 无法限制来访域名的跨域方案
- JSONP跨域 创建script标签,无法确定调用方
- 表单提交跨域
- URL传参跨域
- 服务端代理跨域
- window.name 跨域
- 带域名限制的跨域方案
使用dns-prefetch:<link rel="dns-prefetch" href="https://fonts.googleapis.com/" />
HTML属性crossorigin有啥用?
crossorigin 属性在 <audio>、<img>、<link>、<script> 和 <video> 元素中有效,它们提供对 CORS 的支持,定义该元素如何处理跨源请求,从而实现对该元素获取数据的 CORS 请求的配置。
crossorigin会让浏览器启用CORS访问检查,检查http响应头的Access-Control-Allow-Origin- 对于传统script需要跨域获取的js资源,控制暴露出其报错的详细信息 可以使跨域js暴露出跟同域js同样的报错信息
- 对于
module script,控制用于跨域请求的凭据模式
使用下面的 <script>元素告诉浏览器执行来自 https://example.com/example-framework.js 的脚本且不发送用户凭据。
<script
src="https://example.com/example-framework.js"
crossorigin="anonymous"></script>JavaScript
说说你知道的JavaScript解释器?
JIT(Just-in-time) compilation engines:
- v8。Google Chrome
- Chakra。Edge(Internet Explore)
- Spider Monkey。Mozilla FireFox
- JavaScript Core Webkit。Safari
- Hermes。Meta React Native
Runtime interpreter engines:
- QuickJS
- Boa。Written in Rust
- Rhino。Mozilla
JavaScript为啥被设计为单线程?
与其用途有关,作为浏览器脚本,JavaScript的主要用途是与用户互动、操作DOM。这决定了它只能是单线程。比如,加入JavaScript支持多线程,一个线程添加DOM节点,另一个线程删除DOM节点,这就会带来混乱。
在被设计出来的那个年代来说是一个很好的选择,那个时候很少有多处理器的计算机,而且当时预期由JavaScript处理的代码量相对较少。
自从定时器(setTimeout和setInterval)加入到Web API中,浏览器提供的JavaScript环境就已经逐渐发展到包含任务调度、多线程应用开发等强大特性。
浏览器除了主线程外,后续增加了web worker的能力,允许创建独立的线程。
主线程:处理用户事件、页面绘制。
说下微任务和宏任务?
- 在 JavaScript 中通过 queueMicrotask() 使用微任务 - Web API 接口参考 | MDN
- 深入:微任务与 Javascript 运行时环境 - Web API 接口参考 | MDN
JavaScript运行时:在执行 JavaScript 代码的时候,JavaScript 运行时实际上维护了一组用于执行 JavaScript 代码的代理。每个代理由一组执行上下文的集合、执行上下文栈、主线程、一组可能创建用于执行 worker 的额外的线程集合、一个任务队列以及一个微任务队列构成。除了主线程(某些浏览器在多个代理之间共享的主线程)之外,其他组成部分对该代理都是唯一的。
每个代理都是由事件循环驱动的,事件循环负责收集事件(包含用户事件和其他非用户事件等)、对任务进行排队以便在合适的时机执行回调。然后执行处于等待中的JavaScript任务,然后是微任务,然后在开始下一轮循环之前执行一些必要的渲染和绘制操作。
有以下三种事件循环:
Window事件循环:驱动所有共享同源的窗口(多个同源窗口可能运行在相同的事件循环中,如在窗口中打开新窗口或包含在iframe中)。
Worker事件循环:包含所有形式的worker,如web worker、service worker、shared worker
Worklet事件循环:驱动运行worklet的代理,包含Worklet、AudioWorklet以及PaingWorklet
在每一次事件循环开始迭代的时候运行时执行队列中每个任务,在每次开始迭代之后加入到队列中的任务需要等到下一次迭代开始后才会被执行。
每次当一个任务退出切执行上下文为空时,微任务队列中每一个微任务会依次被执行,直到为空。微任务可以添加微任务,新的微任务在下一次任务开始执行之前,在当前事件循环迭代结束之前执行。
什么是任务?
由执行诸如从头执行一段程序、执行事件回调或一个interval/timeout被触发而调度的任务JavaScript代码。
何时会将任务添加到任务队列?
- 一段新程序或子程序被直接执行时(比如在控制台或一个
<script>元素中运行代码) - 触发了一个事件,将其回调函数添加到任务队列时
- 执行一个由setTimeout或setInterval创建的interval或timeout,以致对应的回调函数被添加到任务队列时。
微任务的执行顺序在所有进行中的任务(pending task)完成之后,在对浏览器的事件循环产生控制之前。
创建微任务的方式:
- Web API:
- JavaScript:
- Promise
聊聊你了解的V8垃圾回收
调用栈的垃圾回收
有一个记录当前执行状态的指针(称为 ESP)指向调用栈中的函数执行上下文。当函数执行完成之后,就需要销毁函数的执行上下文了,这时候,ESP 就帮上忙了,JavaScript 会将 ESP 下移到后面的函数执行上下文,这个下移的过程就是销毁当前函数执行上下文的过程。
堆中的垃圾回收
与栈中的垃圾回收不同的是,栈中无效的内存会被直接覆盖掉,而堆中的垃圾回收需要使用 JavaScript 中的垃圾回收器。
垃圾回收一般分为下面的几个步骤:
通过 GC Root 标记空间中的活动对象和非活动对象 目前 V8 采用 可访问性(reachablility)算法来判断堆中的对象是否为活动对象。这个算法其实就将一些 GC Root 作为初始存活对象的集合,从 GC Root 对象触发,遍历 GC Root 中的所有对象。
- 能够通过 GC Root 遍历到的对象会被认为是可访问的,我们将其标记为活动对象,必须保留
- 如果一个对象无法通过 GC Root 遍历到,那么就认为这个对象是不可访问的,可能需要被回收,并标记为非活动对象。
GC Root通常包括并不限于以下几种:
- 全局
windows对象(位于每个iframe中) - 文档 DOM 树,由可以通过遍历文档到达所有原生 DOM 节点组成
- 存放栈上的变量。
回收非活动对象占据的内存
内存整理
代际假说:
- 大部分对象在内存中存在的时间很短,比如说函数内部的变量,或者块级作用域中的变量,当函数或块级代码块执行结束时,作用域内部定义的变量也会被销毁,这一类对象被分配内存后,很快就会变得不可用。
- 只要不死的对象,都会持续很久的存在,比如说 window、DOM、Web API 等。
代际假说将对象大致分为两种,长寿的和短命的,垃圾回收也顺势把堆分为新生代和老生代两块区域。
V8 也分别使用了两个不同的垃圾回收器来高效的实施垃圾回收:
- 副垃圾回收器,主要负责新生代的垃圾回收。Scavenge 算法
- 主垃圾回收器,主要负责老生代的垃圾回收。标记-清除(Mark-Sweep)
新生区如何晋升为老生区?
- 一些大的对象会被直接分配到老生区
- 在新生区经历两次垃圾回收还能存活,会被晋升
全停顿
垃圾回收操作会暂停 JavaScript 的运行,回收完毕后才会恢复执行,这种行为就是全停顿。
为了降低全停顿所带来的卡顿,V8 引擎采用了增量标记(Incremental Marking) 算法进行优化,将标记过程分为一个个小任务,这些小任务的执行时间比较短,可以穿插在其他的 JavaScript 任务中间执行,这样就不会有明显的卡顿了。
当然,V8 所采用的优化方案不只这一种,而是多种方案综合使用的,除了增量回收还有并行回收、并发回收等。
- 并行回收:垃圾回收器会使用多个辅助线程来并行执行垃圾回收
- 并发回收:回收线程在执行 JavaScript 的过程中,辅助线程在后台执行垃圾回收
说下执行上下文、闭包?
闭包:绑定了执行环境的函数。 闭包的组成部分:
- 环境部分
- 词法环境(所在执行上下文一部分)
- 标识符列表:函数中用到的未声明的变量
- 表达式部分:函数体
在一个函数的执行上下文中包含若干内容:
- 词法环境。当获取this或变量时使用
- 变量环境。声明变量时使用
- 用于恢复代码执行位置的代码执行状态
- 正在被执行的函数
- 使用的基础库和内置对象实例
- 生成器上下文时表示当前生成器
实现一个深拷贝
对于可序列化的对象,可直接使用:JSON.parse(JSON.stringify(obj))。但函数、Symbol、HTML Element、递归数据等许多其他情况会失败。☹️
另一种方式,如果在实现了structuredClone的JavaScript运行时环境下,可使用:structuredClone(obj)。(core-js支持polyfill)
手写深拷贝:
function deepClone (obj, hash = new WeakMap()) {
if (obj === null) return obj;
if (obj instanceof Date) return new Date(obj);
if (obj instanceof RegExp) return new RegExp(obj);
if (typeof obj !== 'object') return obj;
if (hash.has(obj)) return hash.get(obj);
let cloneObj = new obj.constructor();
hash.set(obj, cloneObj);
for (let key in obj) {
if (obj.hasOwnProperty(key)) {
cloneObj[key] = deepClone(obj[key], hash);
}
}
return cloneObj;
}JavaScript装箱转换、拆箱转换?
每一种基本类型如Number、String、Boolean、Symbol在对象中都有对应的类,所谓装箱转换,正是把基本类型转换为对应的对象。
使用装箱机制得到Symbol对象:
const symbolObj = (function() {return this;}).call(Symbol());
console.log(symbolObj instanceof Symbol); // true在JavaScript标准中规定了ToPrimitive函数,它是对象类型到基本类型的转换(拆箱转换) 拆箱转换会尝试调用valueOf和toString来获得拆箱后的基本类型。如果valueOf和toString都不存在或未返回基本类型,则会产生类型错误TypeError
使用Object.prototype.toString.call(obj)判断类型的原理是啥?
Symbol.toStringTag - JavaScript | MDN
大多数内置的对象提供了它们自己的 @@toStringTag 属性。所有内置对象的 @@toStringTag 属性都是不可写的(writable)、不可枚举的(enumerable)但是可配置的(configurable)。
Object.prototype.toString.call(new Map()); // "[object Map]"
Object.prototype.toString.call(function* () {}); // "[object GeneratorFunction]"
Object.prototype.toString.call(Promise.resolve()); // "[object Promise]"能说下前端的模块系统吗?
AMD与CMD的区别?
- 对于依赖的模块,AMD提前执行,CMD是延迟执行
- CMD推崇依赖就近,AMD推崇依赖前置
- AMD的API一个能当多个用,职责单一;CMD每个API都简单纯粹
UMD是AMD和CommonJS的综合产物,AMD用于浏览器,CommonJS用于服务器。UMD则是则是两者的兼容模式,解决了跨平台问题。
CommonJS的实现原理?
在编译过程中,对CommonJS模块代码进行包装放到一个函数中,并将require、exports、module作为形参传入进去。 在模块加载的时候,通过类似eval的函数执行模块包装函数。
ES Module与CommonJS的差异?
- 语法
import/exportrequire/module - ESM静态导入导出,编译过程确定了模块依赖路径,易实现tree shaking;import() 懒加载、代码分割;
- CommonJS同步加载并执行文件;ESM提前加载并执行文件
- CommonJS由JS运行时实现;ESM是语言特性支持
- ESM模块导出的值是动态的,CommonJS导出值是原始值的副本。
Object.is和===有啥区别?
- NaN === NaN -> false; Object.is(NaN, NaN) -> true
- -0 === +0 -> true; Object.is(-0, +0) -> false
0.1 + 0.2 === 0.3?
浮点数类型的值通常表示的是某个数字的近似值。在计算机中,浮点数实际是使用二进制来实现的,但是我们通常想用十进制来完成浮点数运算。这种不匹配性导致了歧义的发生。此外,虽然浮点数通常用来表示实数,然而它的精度是有限。
很多值,无法用二进制精确表示,如 0.1、1/3
测试一个数学运算结果是否落在真实数学结果的一个可接受范围内是比较安全的。这个范围通常被称为机器最小值(EPSILON)或最小单元取整数
new String("foo")和"foo"相等吗?
使用==相等。会进行类型转换 使用===不相等。不会进行类型转换,new String("foo")是一个包装器对象
JS 数组为什么没有负数索引?
JS最初设计希望足够简单(相对Java),于是将数组下标也统一设计成对象属性访问。这样,一个普通对象就可以当作数组来用;所谓数组,相对普通对象唯一本质性的区别就是有一个魔法属性length 。
如果通过索引找不到会上溯到原型链上去找,不仅有害性能也有安全隐患。
数组下标的coerce是ToString而不是ToNumber。(对于属性的key来说不存在负数,只有字符串而已)
typeof null === ‘object’ ?
js在底层存储变量的时候会在变量的机器码的低位1-3位存储其类型信息(000:对象,010:浮点数,100:字符串,110:布尔,1:整数),但是null所有机器码均为0,直接被当做了对象来看待。
const怎么阻止非原始值的重新赋值?
- Object.freeze(注意,它是shadow的)
- TypeScript的as const
使用场景🎬:
- 配置对象
- 常量对象
- 全局状态
- 内部实现(属性或方法)
for...in、 for...of区别? 迭代器协议与可迭代协议区别?内置可迭代对象有哪些?
for…in 遍历对象的可枚举属性(Symbol除外,可用Object.getOwnPropertySymbols)
for…of 遍历可迭代对象
可迭代协议:必须有
@@iterator([Symbol.iterator])方法迭代器协议:实现了一个拥有以下语义(semantic)的
next()方法- next(), 返回
IteratorResult的函数
- next(), 返回
内置可迭代对象:
- Array
- Map/WeakMap
- Set/WeakSet
- String
- TypedArray
- arguments
- NodeList
- Intl.Segments
Promises/A+规范?
手写Promise
class MyPromise {
status = 'pending';
value = null;
reason = null;
onFulfilledCallbacks = [];
onRejectedCallbacks = [];
constructor(handler) {
const resolve = (v) => {
this.status = 'fulfilled';
this.value = v;
this.fulfilledCallbacks.forEach(cb => cb(v));
};
const reject = e => {
this.status = 'rejected';
this.reason = e;
this.rejectedCallbacks.forEach(cb => cb(e));
};
try {
handler(resolve, reject);
} catch (error) {
reject(error)
}
}
then (onFulfilled, onRejected) {
return new MyPromise((resolve, reject) => {
if (this.status === 'rejected') {
try {
const rejectedFromLastPromise = onRejected(this.reason);
if (rejectedFromLastPromise instanceof MyPromise) {
rejectedFromLastPromise.then(resolve, reject);
} else {
reject(rejectedFromLastPromise);
}
} catch (error) {
reject(error);
}
}
if (this.status === 'fulfilled') {
try {
const resolvedFromLastPromise = onFulfilled(this.value);
if (resolvedFromLastPromise instanceof MyPromise) {
resolvedFromLastPromise.then(resolve, reject);
} else {
resolve(resolvedFromLastPromise);
}
} catch (error) {
reject(error)
}
}
if (this.status === 'pending') {
this.onFulfilledCallbacks.push(() => {
try {
const resolvedFromLastPromise = onFulfilled(this.value);
if (resolvedFromLastPromise instanceof MyPromise) {
resolvedFromLastPromise.then(resolve, reject);
} else {
resolve(resolvedFromLastPromise);
}
} catch (error) {
reject(error)
}
});
this.onRejectedCallbacks.push(() => {
try {
const rejectedFromLastPromise = onRejected(this.reason);
if (rejectedFromLastPromise instanceof MyPromise) {
rejectedFromLastPromise.then(resolve, reject);
} else {
reject(rejectedFromLastPromise);
}
} catch (error) {
reject(error);
}
});
}
});
}
}实现new
new操作符做了什么?
- 创建了一个全新的对象。
- 这个对象会被执行
[[Prototype]](也就是__proto__)链接。 - 生成的新对象会绑定到函数调用的
this。 - 通过
new创建的每个对象将最终被[[Prototype]]链接到这个函数的prototype对象上。 - 如果函数没有返回对象类型
Object(包含Functoin,Array,Date,RegExg,Error),那么new表达式中的函数调用会自动返回这个新的对象。 - 怎么模拟实现
function myNew(ctor, ...args) {
// ES6 new.target 指向构造函数
myNew.traget = ctor;
let newObj = Object.create(ctor);
const ctorReturnResult = ctor.apply(newObj, args);
if (typeof ctorReturnResult === 'object' && ctorReturnResult !== null || typeof ctorReturnResult === 'function') return ctorReturnResult;
return newObj;
}实现instanceof
function myInstanceof(left, right) {
left = left.__proto__;
while (true) {
if (!left) return false;
if ((left = left.__proto__) === right.prototype) return true;
}
}- 首先获取类型的原型
- 然后获得对象的原型
- 然后一直循环判断对象的原型是否等于类型的原型,直到对象原型为
null,因为原型链最终为null
实现EventEmitter
function emitter() {
const all = new Map();
return {
all,
on (type, handler) {
if (!all.has(type)) {
all.set(type, []);
}
all.get(type).push(handler);
},
emit (type, ...args) {
if (!all.has(type)) return;
all.get(type).forEach(handler => handler(...args));
},
off (type, handler) {
if (!all.has(type)) return;
all.get(type).splice(all.get(type).indexOf(handler) >>> 0, 1);
}
};
}实现call/apply/bind
function myBind(context = window, ...args) {
if (this === Function.prototype) throw new Error()
const fn = Symbol.for('bind');
context[fn] = this;
const result = context[fn](...args);
delete context[fn];
return result;
}
function myApply(context, args) {
const fn = Symbol.for('apply');
context[fn] = this;
const result = context[fn](...args);
delete result[fn]
return result;
}
function myBind(context, args) {
const _this = this;_
return function(...args2) {
return _this.apply(context, args.concat(args2));
}
}实现柯里化函数
用闭包把参数保存起来,当参数的数量足够执行函数了,就开始执行函数。
function currying(fn, ...args) {
if (args.length >= fn.length) return fn(...args);
return (...args2) => currying(fn, ...args, ...args2)
}实现类似lodash的get方法
const get = (obj, paths, defaultValue) => {
const res = (typeof paths === 'string' ? paths.split('.') : paths).flatMap(s => s.split('[').flatMap(s => s.split(']').filter(Boolean))).reduce((acc, cur) => acc && Reflect.get(acc, cur), obj);
return typeof res === 'undefined' ? defaultValue : res;
}TypeScript中type和interface区别在哪?如何抉择?
- interface无法表示联合类型、映射类型和条件类型,type可以
- interface可以使用extends,type不行(此外,
extends比&更快) - 在同一个scope下重复声明interface会merge(三方库类型扩展很方便),而type会报错
- type隐式实现了索引签名,而interface没有
1
// unions
type A = boolean | string;
// mapped types
type B = { [x:string]: boolean };
// conditional types
type C = A extends boolean ? string : boolean;2
interface A {
name: string;
}
interface B extends A {
age: number;
}
type C = { name: string; } & { age: number };3
interface A {
name: string;
}
interface A {
age: number;
}4
type A = Record<string, boolean>;
interface B { x: number; y: number };
const attrs: B = { x: 1, y: 2 };
// Type 'B' is not assignable to type 'A'.
// Index signature for type 'string' is missing in type 'B'.
const newAttrs: A = attrs;Web框架
解释下CSR、SSR、SSG、ISR、RSC?
- CSR客户端渲染,下载脚本,加载服务端数据,然后渲染
- SSR是服务端渲染,服务端加载数据,渲染HTML,然后客户端下载脚本,然后注水加交互
- SSG、ISR、RSC都是SSR的不同形式。
- SSG是SSR的预处理版本,先在编译时运行SSR,产出HTML(类比预制菜)
- ISR全称Incremental Static Regeneration增量静态再生,是SSR和SSG的结合,第一次请求特定页面将生成的HTML发送并保存(有过期时间),下次再次请求直接返回上次生成的
- RSC在SSR基础上提供Server Component的能力,用组件的方式写服务端逻辑,类似PHP,好处是返回的文件大小降低了。
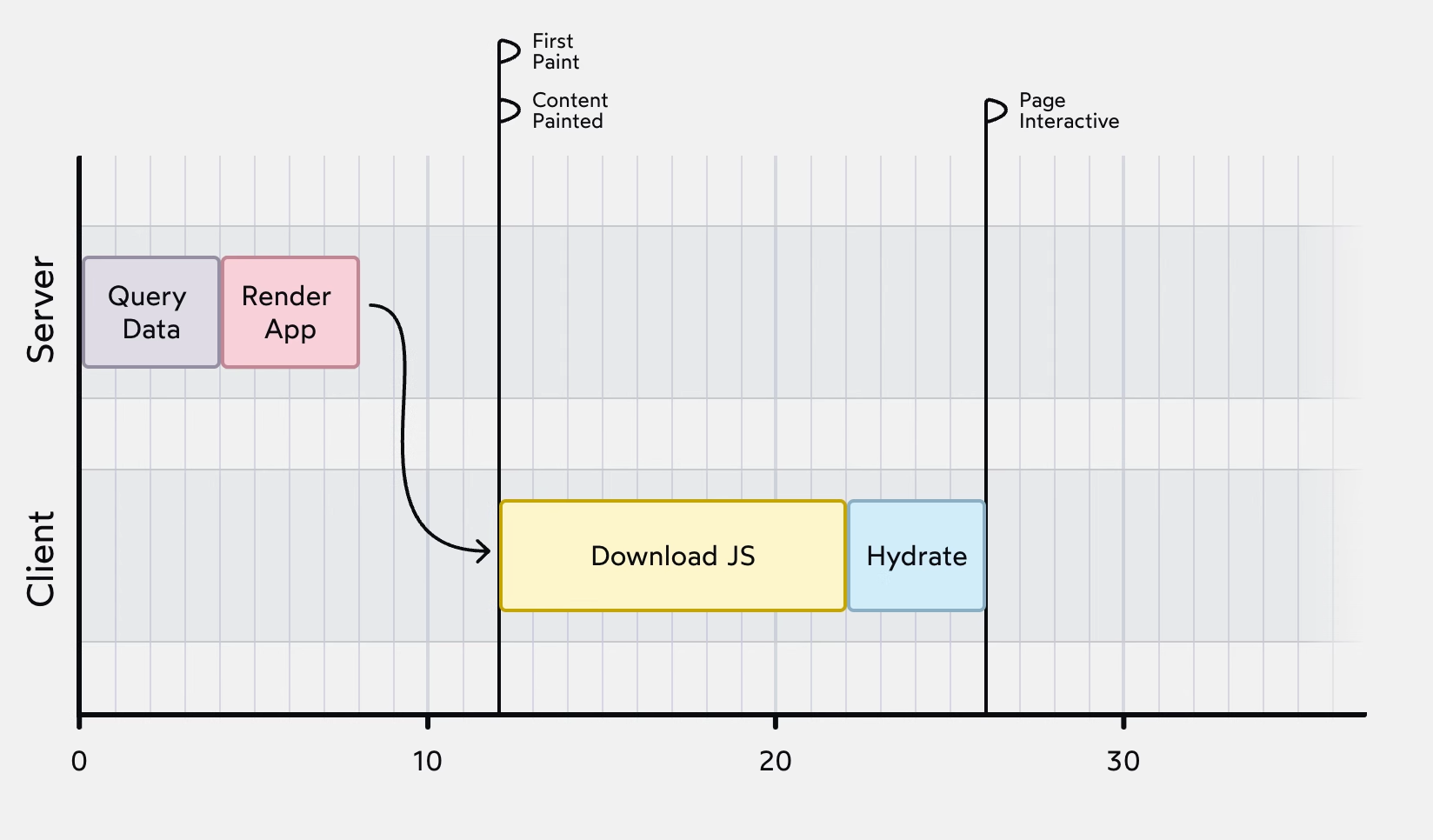 SSR
SSR
Diff DOM
当组件被渲染时,虚拟 DOM 计算新状态和先前状态之间的差异(diffing),并对真实 DOM 进行最小的更改集,以使其与更新的虚拟 DOM 同步(reconciliation)。
Block Virtual DOM
- 静态分析阶段,将树的动态部分提取到 mappings 中(可以在编译时也可以在运行时);
- 通过脏检查比较数据来确定发生了哪些变化。状态变化则通过mappings更新DOM(只设计状态而不是虚拟DOM)
具体步骤
- 不使用React渲染jsx,而是使用million.js,用holes 表示动态变化的部分并传递到虚拟DOM,holes作为动态内容的占位符
- 一旦通过脏检查确定状态变化的内容,即可通过mappings找到各自的节点并直接更新DOM Block Virtual DOM适合的使用场景:
- 静态内容较多。此时可跳过大量静态部分
- 适用于稳定、变化不大的UI树,
Vue
谈谈你对MVVM的理解?
MVVM 是 Model-View-ViewModel 的缩写。MVVM 是一种设计思想。 Model 层代表数据模型,也可以在 Model 中定义数据修改和操作的业务逻辑; View 代表 UI 组件,它负责将数据模型转化成 UI 展现出来,View 是一个同步 View 和 Model 的对象 在 MVVM 架构下,View 和 Model 之间并没有直接的联系,而是通过 ViewModel 进行交互, Model 和 ViewModel 之间的交互是双向的, 因此 View 数据的变化会同步到 Model 中,而 Model 数据的变化也会立即反应到 View 上。 对 ViewModel 通过双向数据绑定把 View 层和 Model 层连接了起来,而 View 和 Model 之间的 同步工作完全是自动的,无需人为干涉,因此开发者只需关注业务逻辑,不需要手动操作 DOM,不需要关注数据状态的同步问题,复杂的数据状态维护完全由 MVVM 来统一管理。
Vue的响应式系统如何创建的?
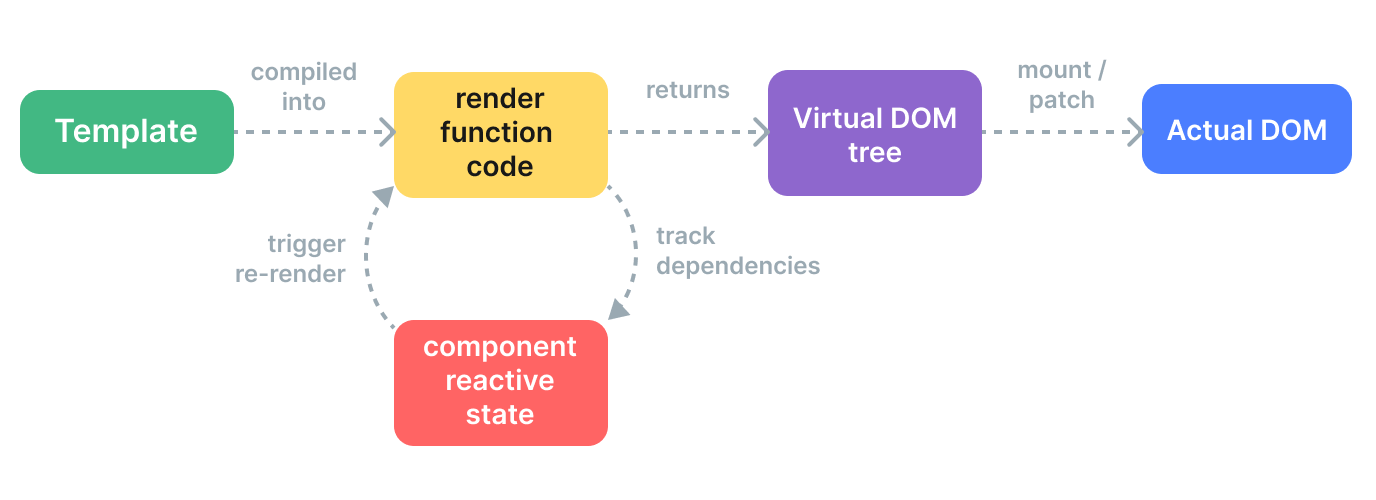
Vue的响应性系统是通过深度转换JavaScript对象为响应式代理来实现的。通过Proxy追踪对象的读写操作。
在track内部,检查当前正在运行的副作用,被将副作用存储在一个全局的WeakMap数据结构中。 在trigger中,查好该属性所有的副作用订阅,并执行它们。
在响应式副作用中,更新视图(调用虚拟DOM渲染函数)。
Vue为何跟推荐使用模板而非渲染函数?
Vue 模板会被预编译成虚拟 DOM 渲染函数。Vue 也提供了 API 使我们可以不使用模板编译,直接手写渲染函数。在处理高度动态的逻辑时,渲染函数相比于模板更加灵活,因为你可以完全地使用 JavaScript 来构造你想要的 vnode。
那么为什么 Vue 默认推荐使用模板呢?有以下几点原因:
- 模板更贴近实际的 HTML。这使得我们能够更方便地重用一些已有的 HTML 代码片段,能够带来更好的可访问性体验、能更方便地使用 CSS 应用样式,并且更容易使设计师理解和修改。
- 由于其确定的语法,更容易对模板做静态分析。这使得 Vue 的模板编译器能够应用许多编译时优化来提升虚拟 DOM 的性能表现。
编译器可以静态分析模板并在生成的代码中留下标记,使得运行时尽可能地走捷径。与此同时,Vue仍旧保留了边界情况时用户想要使用底层渲染函数的能力。称这种混合解决方案为带编译时信息的虚拟 DOM。
提升运行时性能的手段:
- 静态提升。复用、压缩静态内容
- 编译时保留更新类型标记。使用位掩码技术更新和检查:元素所需的更新类型、vnode子节点类型
- 树结构拍平。将结构稳定的部分编译为一个拍平的数据,减少虚拟DOM协调时需要遍历的节点数量,任何静态部分都会被略过。
Vue3组合式API的优势有哪些?
- 更好的逻辑复用
- 更灵活的代码组织
- 更好的类型推导
- 更小的生产包体积
Vue3的渲染机制?
- 编译 Vue模板被编译为渲染函数,即用来返回虚拟DOM树的函数。
- 挂载 运行时渲染器调用渲染函数,遍历返回的VNode并创建实际DOM
- 更新 依赖发生变化,副作用重新执行,创建更新后的VNode并Diff,将必要的更新应用到DOM
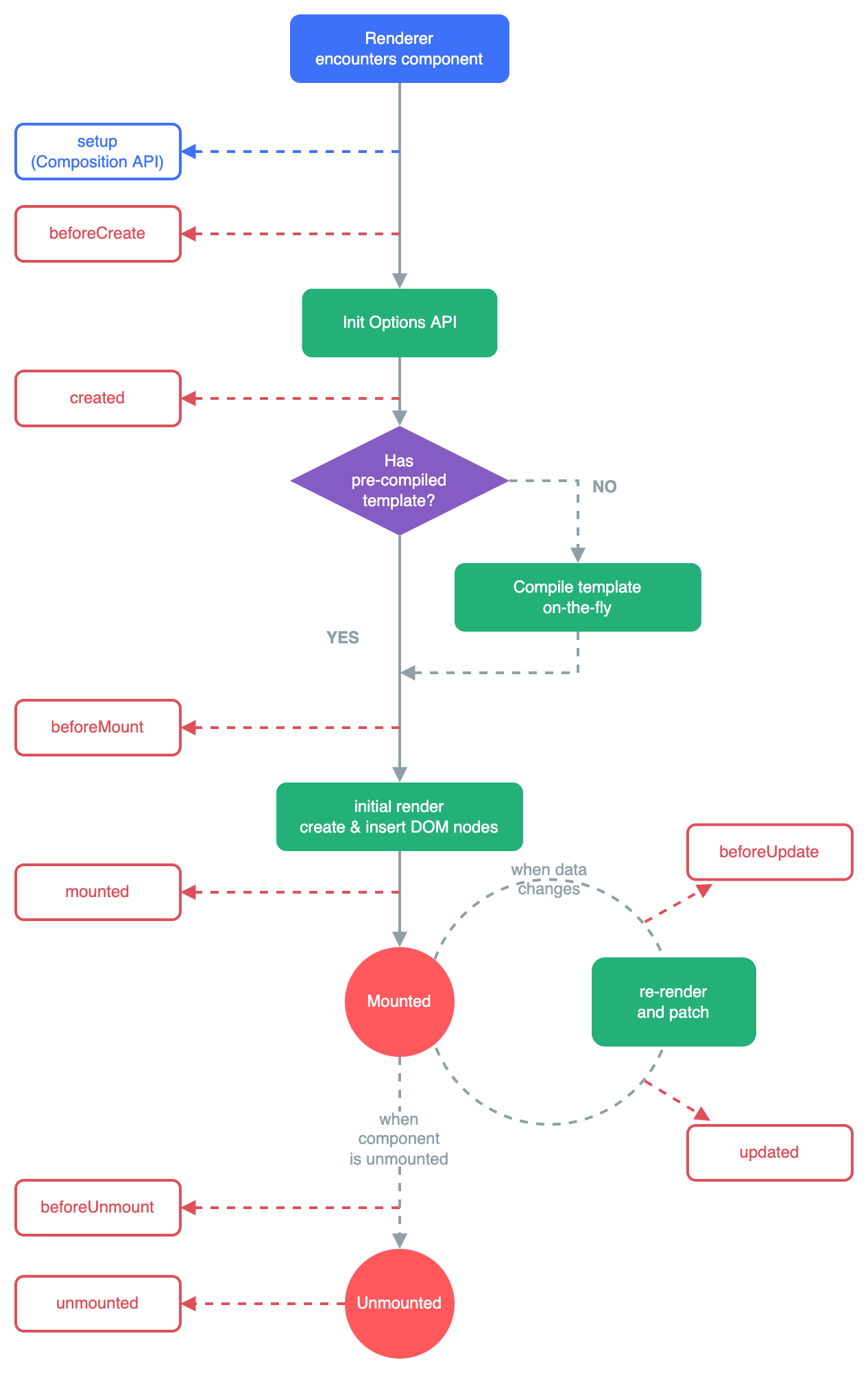
Vue的生命周期?
Vue2和Vue3 Diff算法分别说一下?
简单来说,diff 算法有以下过程
- 同级比较,再比较子节点
- 先判断一方有子节点一方没有子节点的情况(如果新的 children 没有子节点,将旧的子节点移除)
- 比较都有子节点的情况(核心 diff)
- 递归比较子节点
Vue2 的核心 Diff 算法采用了双端比较的算法。同时从新旧 children 的两端开始进行比较,借助 key 值找到可复用的节点,再进行相关操作。相比 React 的 Diff 算法,同样情况下可以减少移动节点次数,减少不必要的性能损耗,更加的优雅。
Vue3.x 借鉴了 ivi 算法和 inferno 算法。在创建 VNode 时就确定其类型,以及在 mount/patch 的过程中采用位运算来判断一个 VNode 的类型,在这个基础之上再配合核心的 Diff 算法,使得性能上较 Vue2.x 有了提升。该算法中还运用了动态规划的思想求解最长递归子序列。
解释一下 vue-router 的完整的导航解析流程是什么?
一次完整的导航解析流程如下:
- 1.导航被触发。
- 2.在失活的组件里调用离开守卫。
- 3.调用全局的 beforeEach 守卫。
- 4.在重用的组件里调用 beforeRouteUpdate 守卫(2.2+)。
- 5.在路由配置里调用 beforeEnter。
- 6.解析异步路由组件。
- 7.在被激活的组件里调用 beforeRouteEnter。
- 8.调用全局的 beforeResolve 守卫(2.5+)。
- 9.导航被确认。
- 10.调用全局的 afterEach 钩子。
- 11.触发 DOM 更新。
- 12.用创建好的实例调用 beforeRouteEnter 守卫中传给 next 的回调函数。
Vue内置组件KeepAlive 实现原理?
KeepAlive组件本身并不会渲染额外的内容,它的渲染函数最终只返回需要被KeepAlive的组件,把这个需要被KeepAlive的组件称为「内部组件」。
KeepAlive组件会对内部组件进行操作,主要在「内部组件」的vnode对象上添加一个标记属性,以便渲染器能够做一些额外处理:
shouleKeepAlive:如果渲染器在执行卸载操作中发现有该属性,则不会真的卸载,而是调用_deActivate函数完成失活(vnode.keepAliveInstance._deActivate(vnode))keepAliveInstance:「内部组件」的vnode上会持有KeepAlive组件实例,在unmount时会访问keepAliveInstance的_deActivate函数- keptAlive:如果「内部组件」已被缓存,则会为其添加一个keptAlive标记,这样当内部组件重新渲染时,渲染器并不会重新挂载它,而会将其激活(执行
vnode.keepAliveInstance._activate(vnode)
失活的本质就是将组件渲染的内容移动到隐藏容器中,激活就是从隐藏容器中搬运回原来容器。(move函数由渲染器提供)
Vue内置组件Teleport实现原理?
本质是为了实现跨DOM层级渲染。
Teleport组件选项中包含process函数,在patch时如果存在__isTeleport则会使用process函数将控制权交给Teleport组件(传递一些渲染器方法)
core/packages/runtime-core/src/components/Teleport.ts at 623ba514ec0f5adc897db90c0f986b1b6905e014 · vuejs/core · GitHub process内部实现大致如下:
- 判断旧的虚拟节点是否存在,决定接下来的操作是挂载还是更新
- 获取挂载点(指定的
to属性对应DOM节点) - 如果是更新,需要判断前后挂载点是否发生了变化,并移动内容
Vue内置组件Transition实现原理?
核心原理:
- 当DOM元素被挂载时,将动效附加到DOM元素上
- 当DOM元素被卸载时,不立即卸载DOM元素,而是等到附加的动效执行完成再卸载
在vnode.transition对象中定义过渡相关钩子函数,渲染器在执行挂载和卸载操作时会优先检查该虚拟节点是否过渡
Vue3如何实现一个防抖的Ref?
function useDebouncedRef<T>(value: T, delay = 200) {
let timer: ReturnType<typeof setTimeout>
return customRef((track, trigger) => {
return {
get: () => {
track()
return value;
},
set: (newValue: T) => {
clearTimeout(timer);
timer = setTimeout(() => {
value = newValue;
trigger();
}, delay)
}
}
})
}为何不建议v-if与v-for一起使用?
把 v-if 和 v-for 同时用在同一个元素上,带来性能方面的浪费(每次渲染都会先循环再进行条件判断)(v-for比v-if优先级高)
Vue3特性开关怎么实现的?
框架层面:源码中使用全局常量+条件判断,包住某些特性相关的代码 开发者层面:通过bundler提供的方式,定义全局常量,如在编译时常量为true则源码中条件为true触发死代码消除
rollup -> @rollup/plugin-replace webpack -> webpack.DefinePlugin
Vue3错误处理如何实现的?
- 给用户提供自定义注册错误处理函数的方式
- 将可能发生错误的代码用函数包一下,函数中用try…catch拦截错误
// error-handler.js
let handlerError = null;
export default {
registerErrorHandler(fn) {
handlerError = fn;
},
}
export function callWithErrorHandling(fn) {
try {
fn()
} catch(e) {
handlerError?.(e);
}
}
// source code
function foo() {
callWithEErrorHandling(() => {
console.log('do something');
})
}用户侧可以使用如下方式注册错误处理函数:
app.config.errorHandler = (e) => {}Vue如何给数组建立响应性?
- 索引与长度 通过索引设置新值会触发length改变,在Set时判断是SET还是ADD,在trigger时触发与length属性相关联的副作用函数即可。 修改length属性,则在trigger时只执行旧长度大于新长度的副作用
- 遍历 在ownKeys拦截函数中,使用length属性作为key建立响应联系
- 追踪时排查使用Symbol作为key的情况
- 数组查找includes 查找子项为对象的出现错误,因为此时函数内的this为代理对象,通过代理对象索引找到的对象也是代理对象,也原始值对应的子项不一样,故会找不到。 Get中判断key是否为查找相关函数,如果是,则执行重写后的方法,先在代理对象上查,找不到再在原始数组上查
- 会修改原数组的方法 这些方法读取length的同时也会更新数组,就导致了循环执行栈溢出,需要重写相关方法(如:push、pop、shift、unshift、splice)在执行完毕前阻止track
Vue如何代理Set(WeakSet)和Map(WeakMap)?
- 修正get 如果读取size属性则使用原对象
- 调用size函数时调用track建立响应联系
- 自定义实现add/delete方法 执行原始对象的add,触发trigger
- 自定义实现set时注意数据污染 要设置的值可能是代理对象,需要设置原始对象
- 实现forEach注意子项转为可代理对象触发响应
- 为了使用代理对象迭代,需要重新实现迭代器协议和可迭代协议
Vue如何处理响应丢失的问题?
提供toRef方法,将响应对象的值转为getter形式并返回,其中getter返回的是响应对象的值
function toRef(obj, key) {
const wrapper = {
get value() {
return obj[key];
},
set value(v) {
obj[key] = v;
}
}
Object.defineProperty(wrapper, '__v_isRef', {
value: true,
});
return wrapper;
}Vue如何实现自动脱ref?
是用Proxy创建个代理对象,get中判断target是否为ref,为ref则返回target.value
function proxyRefs(target) {
return new Proxy(target, {
get(target, key, receiver) {
const value = Reflect.get(target, key, receiver);
return value.__v_isRef ? value.value : value;
},
set(target, key, newValue, receiver) {
const value = target[key];
if (value.__v_isRef) {
value.value = newValue;
return true;
}
return Reflect.set(target, key, newValue, receiver);
}
});
}Vue2双端Diff原理?
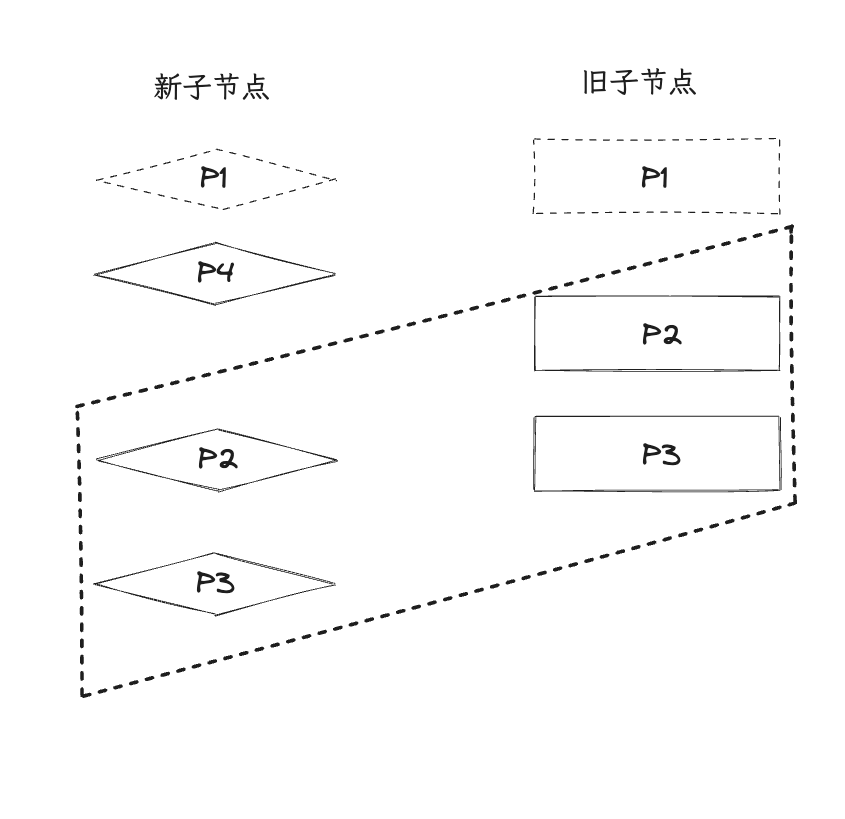
双端Diff算法是一种同时对新旧两组子节点的两个端点进行比较的算法。因此,需要4个索引值,分别指向新旧子节点的端点。
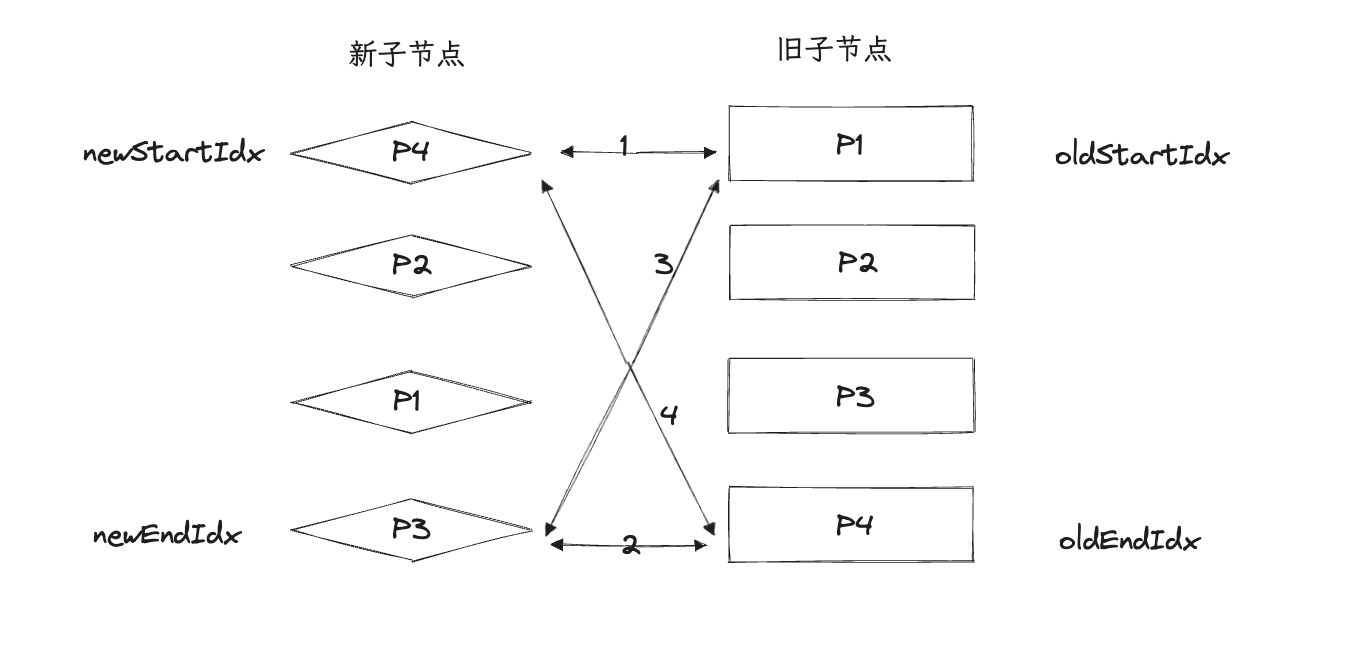
在双端比较中,每一轮都分为4个步骤:
- 比较旧的子节点首位(P1)和新子节点首位(P4) key不同,什么都不做
- 比较旧的末位(P4)与新的末位(P3) key不同,什么都不做
- 比较旧的首位(P1)和新的末位(P3) key不同,什么都不做
- 比较旧的末位(P4)与新的首位(P4) key相同,复用旧的DOM(将旧的P4所属DOM移动到首位) 将oldEndIdx与newStartIdx各向前移动一步,继续开始从第一步开始
在整个循环中,条件为:头部索引值小于等于尾部索引值则继续执行 简单实现如下:
while (newStartIdx <= newEndIdx && oldStartIdx <= oldEndIdx) {
if (!oldStartVNode) {
oldStartVNode = oldChildren[++oldStartIdx];
} else if (!oldEndVNode) {
oldEndVNode = oldChildren[--oldEndIdx];
} else if (oldStartVNode.key === newStartVNode.key) {
// 调用patch在oldStartVNode和newStartVNode打补丁
patch(oldStartVNode, newStartVNode, container);
// 更新索引,指向下一位置
oldStartVNode = oldChildren[++oldStartIdx];
newStartVNode = newChildren[++newStartIdx];
} else if (oldEndVNode.key === newEndVNode.key) {
patch(oldEndVNode, newEndVNode, container);
oldEndVNode = oldChildren[--oldEndIdx];
newEndVNode = newChildren[--newEndIdx];
} else if (oldStartVNode.key === newEndVNode.key) {
patch(oldStartVNode, newEndVNode, container);
oldStartIdx = oldChildren[++oldStartIdx];
newEndVNode = newChildren[--newEndIdx];
} else if (oldEndVNode.key === newStartVNode.key) {
patch(oldEndVNode, newStartVNode, container);
oldEndVNode = oldChildren[--oldEndIdx];
newStartVNode = newChildren[++newStartIdx];
} else {
// 遍历旧的children,找到与newStartVNode.key相同的节点
const idxInOld = oldChildren.findIndex(node => node.key === newStartVNode.key);
// 大于0说明原来不在头部,新的被移动到了头部
if (idxInOld > 0) {
const vnodeToMove = oldChildren[idxInOld];
patch(vnodeToMove, newStartVNode, container);
// 将vnode移动到旧的头部节点之前
insert(vnodeToMove.el, container, oldStartVNode.el);
// 因为已被移动,所以将旧的节点设置为undefined
oldChildren[idxInOld] = undefined;
} else {
// 说明这是个新节点,原来就没有。创建新Node插入到旧的头部节点之前
patch(null, newStartVNode, container, oldStartVNode.el);
}
// 更新newStartIdx
newStartVNode = newChildren[++newStartIdx];
}
}
// 最后检查剩余没匹配上的节点(可能被删除?)
if (newStartIdx <= newEndIdx || oldStartIdx <= oldEndIdx) {
if (newStartIdx > newEndIdx) {
// 说明newChildren已经遍历完了,oldChildren还有剩余,说明这些节点是不需要的,直接删除
for (let i = oldStartIdx; i <= oldEndIdx; i++) {
unmount(oldChildren[i]);
}
} else {
// 说明oldChildren已经遍历完了,newChildren还有剩余,说明这些节点是新增的,直接插入到旧的头部节点之前
for (let i = newStartIdx; i <= newEndIdx; i++) {
patch(null, newChildren[i], container, oldChildren[oldStartIdx].el);
}
}
}Vue3快速Diff原理?
- 预处理,先处理新旧两组子节点中相同的前置节点和相同的后置节点
- 根据节点索引关系,构造出最长递增子序列,指向的节点就是不需要移动的节点
function fastDiff (n1, n2, container) {
const newChildren = n1.children;
const oldChildren = n2.children;
// 处理相同的前置节点
// 索引j指向新旧两组子节点开头
let j = 0;
let oldVNode = oldChildren[j];
let newVNode = newChildren[j];
// while 向后遍历,找到不相同的节点为止
while (
oldVNode.key === newVNode.key &&
oldVNode.tag === newVNode.tag
) {
patch(oldVNode, newVNode, container);
j++;
oldVNode = oldChildren[j];
newVNode = newChildren[j];
}
// 更新相同的后置节点
// 索引oldEnd指向旧组子节点末尾
let oldEnd = oldChildren.length - 1;
// 索引newEnd指向新组子节点末尾
let newEnd = newChildren.length - 1;
oldVNode = oldChildren[oldEnd];
newVNode = newChildren[newEnd];
// while 从后向前遍历,找到不相同的节点为止
while (
oldVNode.key === newVNode.key &&
oldVNode.tag === newVNode.tag
) {
patch(oldVNode, newVNode, container);
oldEnd--;
newEnd--;
oldVNode = oldChildren[oldEnd];
newVNode = newChildren[newEnd];
}
// 预处理之后如果满足以下条件,说明 j --> newEnd 之间的节点是新的
if (j > oldEnd && j <= newEnd) {
const anchorIndex = newEnd + 1;
// 锚点元素
const anchor = anchorIndex < newChildren.length ? newChildren[anchorIndex].el : null;
while (j <= newEnd) {
patch(null, newChildren[j++], container, anchor);
}
} else if (j > newEnd && j <= oldEnd) {
// j --> oldEnd之间的节点是要删除的
while (j <= oldEnd) {
unmount(oldChildren[j++]);
}
} else {
// 其他非理想情况
const count = newEnd - j + 1;
// 构造source数组,长度为未处理节点的数量
const source = new Array(newEnd - j + 1).fill(-1);
const oldStart = j;
const newStart = j;
let moved = false;
let pos = 0;
// 更新过的节点数量
let patched = 0;
// 构建索引表
const keyIndex = {};
for (let i = newStart; i <= newEnd; i++) {
keyIndex[newChildren[i].key] = i;
}
// 遍历旧的一组子节点中剩余
for (let i = oldStart; i <= oldEnd; i++) {
oldVNode = oldChildren[i];
// 更新的节点,小于等于需要更新的节点
if (patched <= count) {
const k = keyIndex[oldVNode.key];
if (typeof k !== 'undefined') {
newVNode = newChildren[k];
// 说明该节点在新的一组中存在,需要移动
patch(oldVNode, newVNode, container);
patched++;
source[k - newStart] = i;
// 判断是否需要移动
if (k < pos) {
moved = true;
} else {
pos = k;
}
} else {
// 说明该节点在新的一组中不存在,需要删除
unmount(oldVNode);
}
} else {
// 卸载多余节点
unmount(oldVNode);
}
}
if (moved) {
// 需要进行DOM移动操作
// 计算最长递增子序列的索引
const seq = lis(source);
// s指向最长递增子序列的末尾
let s = seq.length - 1;
// i指向新组子节点的末尾
let i = count - 1;
for (; i >= 0; i--) {
if (source[i] === -1) {
// 需要挂载的新节点
// 在新节点的位置
const pos = i + newStart;
newVNode = newChildren[pos];
const nextPos = pos + 1;
const anchor = nextPos < newChildren.length ? newChildren[nextPos].el : null;
patch(null, newVNode, container, anchor);
} else if (i !== seq[s]) {
// 该节点需要移动
const pos = i + newStart;
newVNode = newChildren[pos];
const nextPos = pos + 1;
const anchor = nextPos < newChildren.length ? newChildren[nextPos].el : null;
insert(newVNode.el, container, anchor);
} else {
// 该节点不需要移动
s--;
}
}
}
}
}如何实现异步组件?
需要实现的功能:
- 指定加载出错时渲染的组件
- 指定Loading组件及展示该组件的延迟时间
- 指定超时时长
- 加载失败提供重试机制
function defineAsyncComponent (options) {
if (typeof options === 'function') {
options = { loader: options };
}
const { loader } = options;
let innerComp = null;
// 记录重试次数
let retries = 0;
// 封装load函数用于异步加载组件
function load () {
return loader.catch(err => {
if (options.onError) {
return new Promise((resolve, reject) => {
const retry = () => {
resolve(load());
retries++;
};
const fail = () => reject(err);
// 调用用户自定义的错误处理函数 来决定是否重试
options.onError(retry, fail, retries);
});
} else throw err;
});
}
return {
name: 'AsyncComponentWrapper',
setup () {
const loaded = ref(false);
const error = shadowRef(null);
const loading = ref(false);
let loadingTimer = null;
if (options.delay) {
loadingTimer = setTimeout(() => {
loading.value = true;
}, options.delay);
} else loading.value = true;
load()
.then(comp => {
innerComp = comp;
loaded.value = true;
})
.catch(err => {
error.value = err;
})
.finally(() => {
loading.value = false;
clearTimeout(loadingTimer);
});
return () => {
if (loaded.value) {
return innerComp;
} else if (error.value && options.errorComponent) {
return {
type: options.errorComponent,
props: { error: error.value },
};
} else if (loading.value && options.loadingComponent) {
return {
type: options.loadingComponent,
}
} else {
return {
type: Text,
children: '',
};
}
};
},
};
}Svelte
React
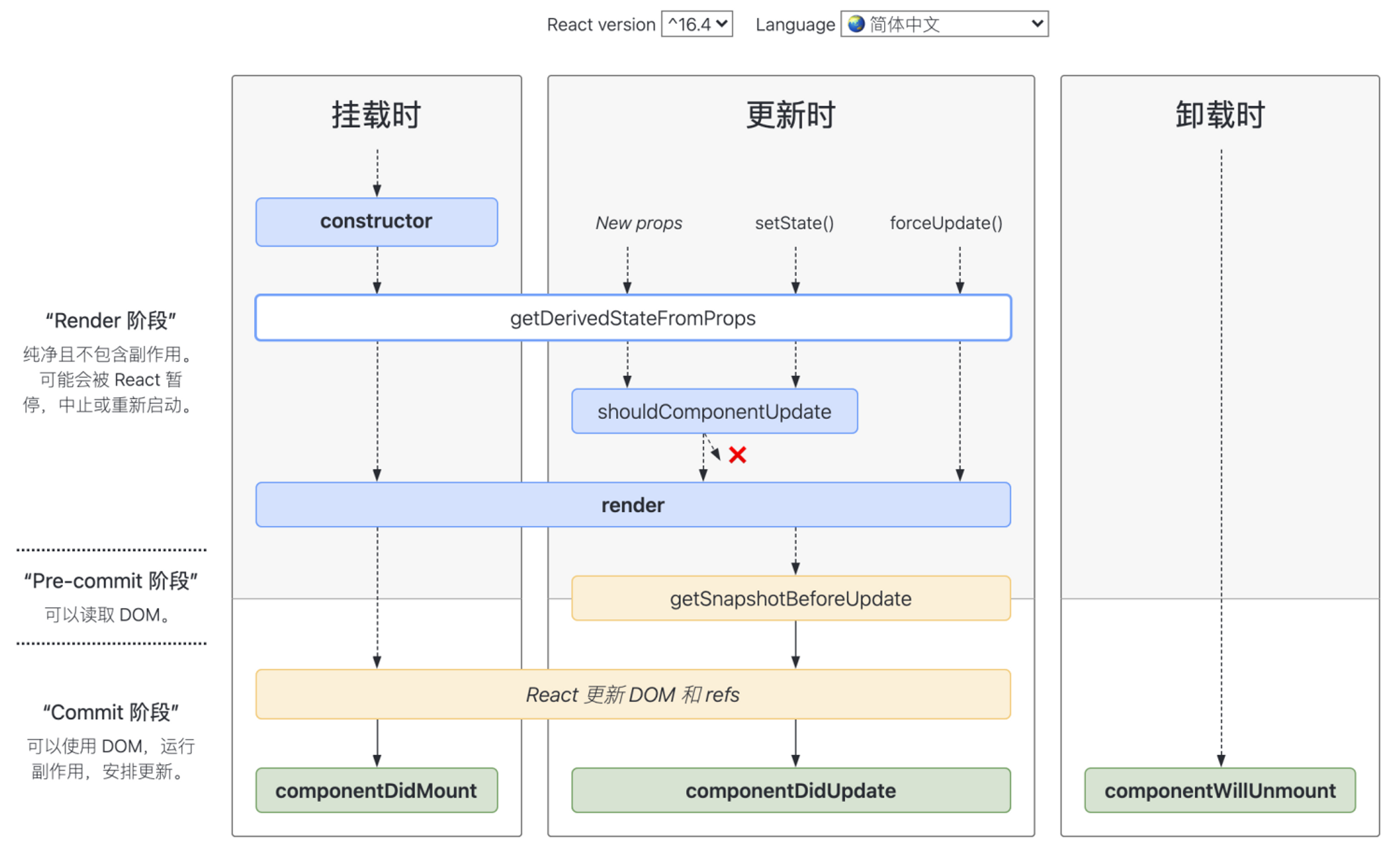
为啥会有Suspense组件?原理是啥?使用场景有哪些?
为了解决客户端的CLS问题,Cumulative Layout Shift累计布局偏移 
原理:类似Error Boundary,再通过try..catch..finally实现子组件消息上报,throw一个Promise,Suspense基于Promise的状态决定子组件的加载状态。
场景:
- 等一组组件全部加载完成,一次性渲染
- 加载新内容时显示旧内容(useDeferredValue)
- 路由切换时等新页面加载完成再切过去(基于startTransition + useTransition)
- 按需加载(基于
React.lazy)
SSR面临的问题:
- 展示任何东西之前需要获取所有东西;
- 需要加载所有JS才能开始水化;
- 与任何东西交互之前,都必须水化任何东西,即不支持渐进式水化
React对上述问题的解同样是Suspense,通过Streaming HTML + Selective Hydration,这是React18主打功能之二
什么是forward refs?
forwardRef将组件的DOM节点通过ref的方式暴露给父组件
const ButtonElement = React.forwardRef((props, ref) => (
<button ref={ref} className="CustomButton">
{props.children}
</button>
));
// Create ref to the DOM button:
const ref = React.createRef();
<ButtonElement ref={ref}>{'Forward Ref'}</ButtonElement>也可通过useImperativeHandle改变需要暴露的ref
useLayoutEffect和useEffect区别?
在 React 中,useEffect 和 useLayoutEffect 分为两个阶段: render 阶段和 commit 阶段。这两个阶段分别发生在组件的渲染过程中,以确保正确地处理副作用
render阶段: 函数组件开始渲染的时候,创建出对应的 hook 链表挂载到 workInProgress 的 memoizedState 上,并创建 effect 链表,但是基于上次和本次依赖项的比较结果;commit阶段: 异步调度useEffect,layout阶段同步处理useLayoutEffect的effect,也就是在浏览器进行布局layout和回执paint之前同步执行。等到commit阶段完成,更新应用到页面上之后,开始处理useEffect产生的effect;
react 在 commit 阶段,它又分为三个小阶段: before mutation、mutation、layout。 其中具体操作 dom 的阶段是 mutation,操作 dom 之前是 before mutation,而操作 dom 之后是 layout。 layout 阶段在操作 dom 之后,所以这个阶段是能拿到 dom 的,ref 更新是在这个阶段,useLayoutEffect 回调函数的执行也是在这个阶段。
整体流程上都是先在 render 阶段,生成 effect,并将它们拼接成链表,存到 fiber.updateQueue 上,这些 effect 表示在组件渲染后需要执行的副作用操作,如数据获取、订阅事件等,最终带到 commit 阶段被处理。
useEffect 生成的 effect 会进入 Scheduler 调度,在浏览器空闲时异步执行,不会阻塞渲染,这样可以避免影响用户界面的响应性。
useLayoutEffect 生成的 effect 会在浏览器 layout 阶段之前同步执行,这可能会阻塞渲染,因此需要谨慎使用,以避免性能问题。
如何解决在服务端渲染中useLayoutEffect不可用的报错?
- 替换为useEffect
- 将组件改为仅在客户端渲染(Suspense+windows检测抛错)
- 只在水合之后渲染使用了
useLayoutEffect的组件。isMounted + useEffect - 如果是外部数据响应更新布局信息,则可以使用
useSyncExternalStore替代
useSyncExternalStore是干啥的?
用于集成外部非react的状态管理库
什么是调解(reconciliation)?
当组件的props或state发生更改时,React 通过将新返回的元素与先前呈现的元素进行比较来确定是否需要实际的 DOM 更新。当它们不相等时,React 将更新 DOM 。此过程称为reconciliation。
错误边界是啥?
错误边界是在其子组件树中的任何位置捕获 JavaScript 错误、记录这些错误并显示回退 UI 而不是崩溃的组件树的组件。 如果一个类组件定义了一个名为 componentDidCatch(error, info) 或 static getDerivedStateFromError() 新的生命周期方法,则该类组件将成为错误边界
不会被捕获的情况:
- 事件处理器
实际项目中可使用react-error-boundary
RSC怎么实现的?
- 当用户访问应用时,通知server渲染App组件,拿到App组件的流式数据后拼成React组件需要的数据形式,最终渲染到页面
- server拿到
/?rsc_id=App&props=...后,针对use client;和use server;分别处理,返回额外的id、typeof、bound等元信息
返回的格式如下:
1:I{"id":"foooooooo","chunks":[],"name":"Foo","async":true}0:["$","div",null,{"children":[["$","h1",null,{"children":"Hello World"}],["$","$L1",null,{}]]}]
$表示React Element,$L表示Lazy Node,会讲其用React.lazy包装返回,$L1的1表示chunk id
哪些情况会触发re-render?如何防止?
- 状态变化
- 父组件re-render
- context变化
- hooks变化
props变化会导致re-render?其实不会,props向上追溯到state变更,是state变更导致父组件re-render从而引发子组件re-render,而不是由props变更引起,触发使用了React.memo
如何避免父组件导致的re-render? 使用React.memo。为啥这不是默认行为?想不re-render,检查props是否变更导致的消耗可能更大!
在Dan的文章在你写memo()之前,需要考虑两个方法将re-render限制在一个很小的范围:
- 状态下移,把可变的部分拆到平行组件中,如
<Changed /><Expensive /> - 把内容上移,把可变的部分拆到父组件中,如
<Changed><Expensive /></Changed>,只要props.children没变化,就不会触发子组件re-render
上面第二点也可以用其他props属性,如:<Changed content={<Expensive />} />,这种方法叫做「Components as props」
什么时候应该用useMemo/useCallback?
- React.memo过的组件的props
- useEffect、useMemo、useCallback中非原始值的依赖应该用
- 重消耗的部分应该用,例如生成渲染树
JavaScript有原始值与引用值的区分,由于props和hook deps都会做shadow equal,使用时尽量避免使用引用值,避免不了需用useMemo/useCallback包一下
如何防止Context导致的re-render?
- memo context value
- 拆分data和API(getter、setter)
- 把数据拆小
- 使用context-selector,例如use-context-selector
如何定位re-render?
- 借助react devtools的record功能,通过录制的方式排查
- 借助外部工具,如:why-did-render或tilg
React合成事件?
React并不是将click事件绑定到了div的真实DOM上,而是在document处监听了所有的事件,当事件发生并且冒泡到document处的时候,React将事件内容封装并交由真正的处理函数运行。这样的方式不仅仅减少了内存的消耗,还能在组件挂在销毁时统一订阅和移除事件。
如何阻止事件冒泡? 除此之外,冒泡到document上的事件也不是原生的浏览器事件,而是由react自己实现的合成事件(SyntheticEvent)。因此如果不想要是事件冒泡的话应该调用event.preventDefault()方法,而不是调用event.stopProppagation()方法。
实现合成事件的目的?
- 合成事件首先抹平了浏览器之间的兼容问题,另外这是一个跨浏览器原生事件包装器,赋予了跨浏览器开发的能力;
- 对于原生浏览器事件来说,浏览器会给监听器创建一个事件对象。如果你有很多的事件监听,那么就需要分配很多的事件对象,造成高额的内存分配问题。但是对于合成事件来说,有一个事件池专门来管理它们的创建和销毁,当事件需要被使用时,就会从池子中复用对象,事件回调结束后,就会销毁事件对象上的属性,从而便于下次复用事件对象。
什么是 React Fiber? 它解决了什么问题?
Fiber 是 React v16 中新的 reconciliation 引擎,或核心算法的重新实现。React Fiber 的目标是提高对动画,布局,手势,暂停,中止或者重用任务的能力及为不同类型的更新分配优先级,及新的并发原语等领域的适用性。
React Fiber 的目标是提高其在动画、布局和手势等领域的适用性。它的主要特性是 incremental rendering: 将渲染任务拆分为小的任务块并将任务分配到多个帧上的能力。
核心思想:Fiber 也称协程或者纤程。它和线程并不一样,协程本身是没有并发或者并行能力的(需要配合线程),它只是一种控制流程的让出机制。让出 CPU 的执行权,让 CPU 能在这段时间执行其他的操作。渲染的过程可以被中断,可以将控制权交回浏览器,让位给高优先级的任务,浏览器空闲后再恢复渲染。
为什么 useState 要使用数组而不是对象?
- 如果 useState 返回的是数组,那么使用者可以对数组中的元素命名,代码看起来也比较干净
- 如果 useState 返回的是对象,在解构对象的时候必须要和 useState 内部实现返回的对象同名,想要使用多次的话,必须得设置别名才能使用返回值
这里可以看到,返回对象的使用方式还是挺麻烦的,更何况实际项目中会使用的更频繁。
总结:useState 返回的是 array 而不是 object 的原因就是为了降低使用的复杂度,返回数组的话可以直接根据顺序解构,而返回对象的话要想使用多次就需要定义别名了。
那为什么不要在循环、条件或嵌套函数中调用 Hook 呢?
因为 Hooks 的设计是基于数组实现。在调用时按顺序加入数组中,如果使用循环、条件或嵌套函数很有可能导致数组取值错位,执行错误的 Hook。当然,实质上 React 的源码里不是数组,是链表。
React 16.x的三大新特性 Time Slicing、Suspense、 hooks
- Time Slicing(解决CPU速度问题)使得在执行任务的期间可以随时暂停,跑去干别的事情,这个特性使得react能在性能极其差的机器跑时,仍然保持有良好的性能
- Suspense (解决网络IO问题)和lazy配合,实现异步加载组件。 能暂停当前组件的渲染, 当完成某件事以后再继续渲染,解决从react出生到现在都存在的「异步副作用」的问题,而且解决得非的优雅,使用的是 T异步但是同步的写法,这是最好的解决异步问题的方式
- 提供了一个内置函数componentDidCatch,当有错误发生时,可以友好地展示 fallback 组件; 可以捕捉到它的子元素(包括嵌套子元素)抛出的异常; 可以复用错误组件。
Hooks更新机制?
对于函数组件来说,其 fiber 上的 memorizedState 专门用来存储 hooks 链表,每一个 hook 对应链表中的每一个元素,最终与其他的 effect 链表形成环形链表。
单个的 effect 对象包括以下几个属性,其中在代码中有如下定义:
const effect: Effect = {
tag,
create,
destroy,
deps,
// Circular
next: (null: any),
};- create: 传入 useEffect 函数的第一个参数,即回调函数;
- destroy: 回调函数 return 的函数,在该 effect 销毁的时候执行;
- deps: 依赖项;
- next: 指向下一个 effect;
- tag: effect 的类型,区分是 useEffect 还是 useLayoutEffect;
如何理解React hooks上的一些使用误区?
React Hooks 使用误区,驳官方文档 React useEvent:砖家说的没问题
RFC: useEvent by gaearon · Pull Request #220 · reactjs/rfcs · GitHub
- 使用useRef解决延迟调用的闭包问题
- useCallback需要和React.memo/
shouldComponentUpdate配合使用,没事别用useCallback
小程序
小程序跨端框架实现原理?
以Remax为例,其通过react-reconciler实现小程序端的渲染器。 小程序对代码屏蔽了DOM操作,代码运行在worker线程中,无法直接操作视图层的DOM。remax通过引入VNode,让React在reconciliation阶段不是改变DOM,而是更新VNode。在React更新完成之后,调用节点的toJSON方法,将VNode变为JSON对象,并作为小程序Page的data。
在模板中通过该data渲染出页面:
<block a:for="{{root.children}}" a:key="{{item.id}}">
<template is="{{'REMAX_TPL_' + item.type}}" data="{{item: item}}" />
</block>
<template name="REMAX_TPL_view">
<view class="{{item.props['className']}}">
<block a:for="{{item.children}}" key="{{item.id}}">
<template is="{{'REMAX_TPL_' + item.type}}" data="{{item: item}}" />
</block>
</view>
</template>
<template name="REMAX_TPL_text">
<text>
<block a:for="{{item.children}}" key="{{item.id}}">
<template is="{{'REMAX_TPL_' + item.type}}" data="{{item: item}}" />
</block>
</text>
</template>
<template name="REMAX_TPL_plain-text">
<block>{{item.text}}</block>
</template>小程序跨端框架类型?
- 静态编译型(编译时) 代表框架:uniapp、taro1/2、MorJS 实现原理:在编译过程将Vue/React的DSL语法,利用babel工具通过AST转译为小程序模板语法,使用Vue管理数据,小程序管理事件。 优点:性能好 缺点:能力受限,新语法必须框架层面支持
- 原生增强型 代表框架:MPX 实现原理:提供一系列增强的模板指令和语法,只需要转换时对指定语法进行处理 优点:运行时性能极佳, 缺点:需要整套学习小程序相关功能,有一定的迁移成本
- 动态渲染型 代表框架:Rax、Remax、Taro3、Kbone 实现原理:利用生成的VNode作为Page的data,并使用小程序渲染模板递归渲染出页面。 优点:重运行时,可直接使用框架语法,学习成本低;尽量模拟Web相关API与DOM,大部分场景可复用Web端代码 缺点:代码体积会较大;性能较差
HTML
src和href的区别?
首先需要了解一个概念:替换型元素。常见的替换型元素有:script、img、video、audio、iframe
凡是替换型元素,都是用src属性引用文件,链接型元素使用href属性。
这也就解释了,为何style标签不能使用src,只能使用link+href引入样式的问题了🙋
DTD是什么?
DTD全称是Document Type Definition,也就是文档类型定义。
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">SGML(Standard generalized markup language)用DTD定义每一种文档类型,HTML属于SGML,在HTML5之前,HTML都是使用符合SGML规定的DTD。但这些复杂的DTD写法并没有实际作用(浏览器并不会用SGML引擎解析它们),因此到了HTML5干脆放弃了SGML子集的坚持,规定了简单易记的DTD:
<!DOCTYPE html>如何实现给图片设置部分区域可点击?
usemap属性+<map> HTMLImageElement: useMap property - Web APIs | MDN
什么是OGP?有何作用?
OGP全称Open Graph protocol,Facebook在2010年推出的一组网页元信息标记协议,是一组为社交分享而生的Meta标签。
如果网页采用OG协议,分享结果会在支持OG协议的网站进行结构化展示,这样站点在被链接分享时会有更丰富的内容展示。 
设置方法很简单,只需要在header内添加几个meta标签即可:
<meta property="og:title" content="显示的标题" />
<meta property="og:type" content="对象类型" />
<meta property="og:url" content="分享的url地址" />
<meta property="og:image" content="缩略图地址" />
<meta property="og:description" content="显示的描述信息" />
<meta property="og:site_name" content="网站名称" />更多的属性设置,参考官网:The Open Graph protocol
以OG官网为例,其设置如下: 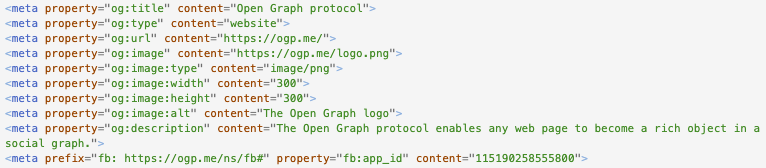
在 facebook,twitter 等网站,有分享卡片检测工具,可利用这些工具,检测分享设置是否成功。
- twitter 分享检测: https://cards-dev.twitter.com/validator
- facebook 分享检测: https://developers.facebook.com/tools/debug/sharing/
- linkedin 分享检测: https://www.linkedin.com/post-inspector/inspect/
CSS
如何通过flex实现两个子元素左上、右下布局?
使用align-self,定义子项的交叉轴对齐方式
Module bundlers
Webpack loader和plugin的区别?
- loader在打包文件之前;plugin贯穿整个编译周期
- loader是个文件转换器;plugin则会在webpack各个生命周期处理输出结果,做各种事情
Webpack中module、chunk、bundle、vendor区别是啥?
- 项目源码中所有资源都属于module
- 在bundling过程中产生的代码成为chunk,chunk有不同类型(entry、child) 产生chunk的途径:
- entry入口
- 异步加载模块
- 代码分割
- bundle包含了加载和编译的最终源文件
- vendor是指将三方库打包提取出一个单独的bundle文件
Webpack中魔法注释webpackPrefetch和webpackPreload有啥区别?
webpackPrefetch 会在浏览器闲置下载文件,webpackPreload 会在父 chunk 加载时并行下载文件。
Webpack生命周期有哪些?
Webpack工作流程最核心的模块Compiler、Compilation
Compiler构建器分为3个阶段:
- 初始化阶段
- environment 创建完Compiler实例,执行插件apply方法前触发
- afterEnvironment
- entryOption
- afterPlugins
- afterResolvers 解析resolver配置后触发
- 构建过程阶段
- normalModuleFactory
- contextModuleFactory
- beforeRun
- run
- beforeCompile
- compile
- thisCompilation
- make 会执行模块编译到优化的完整过程
- 产物生成阶段
- shouldEmit、emit、assetEmitted、afterEmit 在构建完成后,处理产物的过程中触发
- failed、done 达到最终结果状态时触发
Webpack优化手段有哪些?

优化3法宝:缓存、延迟处理、Native code
大致分为3个方向:
- 减少执行编译的模块
- 提升单个模块的编译速度
- 并行构建提升整体效率
基于时间的分析工具:speed-measure-webpack-plugin 基于产物内容的分析工具:webpack-bundle-analyzer
减少编译的模块,如:
- 按需引入工具类包
- 配置Externals。从输出中排除依赖,替换为CDN
- DllPlugin。将不频繁变动的包提前打包好,后续再打包会直接跳过
- IgnorePlugin排除不需要的文件,如moment的国际化文件
提升单个模块的构建速度:
- include/exclude
- noParse
- SourceMap
- TypeScript编译优化。如果使用ts-loader,忽略类型检查;
- Resolve。指定构建时查找模块文件的规则
并行构建提升性能:
- HappyPack
- thread-loader。在特定loader上开启多进程
- parallel-webpack。如果有多个子配置可使用并发构建,串行执行
打包阶段提效:
- TerserWebpackPlugin。缓存和并发
- MiniCssExtractPlugin。异步加载、无重复编译
其他:
- 代码分割。多入口打包、动态加载、分包加载、提取公共模块
- Tree Shaking。
optimization.usedExports: true(注意babel-loader导致的tree shaking失效,被打包为了commonjs。8.x修复或preset-env module设置为false) - Scope Hoisting作用域提升。合并多个模块到一个函数中
- sideEffect 模块标记有无副作用,利于摇树优化。
缓存:
- babel-loader。cacheDirectory
- cache-loader。多其他loader生效 多使用splitChunks优化缓存命中率
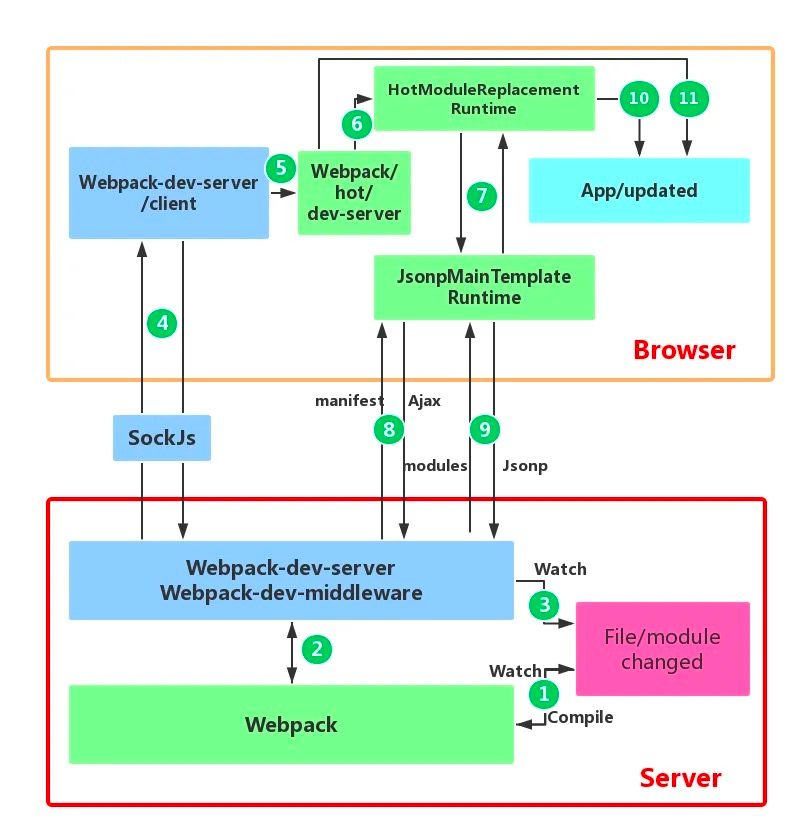
Webpack如何实现热更新?
Hot Module Replacement | webpack
先看下HMR的API和使用场景:
// 接收自己更新,更新后重复执行自己,不往上冒泡
module.hot.accept();
// 接收依赖更新,更新后执行回调函数,不往上冒泡
module.hot.accept(['dep1'], () => {
console.log('dep1 changed');
});
// 让自己失效并冒泡。通常在accept之后遇到一些场景又希望自己失效
module.invalidate();
// 标记一些依赖为不可更新,这些以来更新会触发页面reload
module.hot.decline(['dep1']);
// 同上,标记自己不可更新
module.hot.decline();
// 设置或移除当前模块被自动替换时执行的回调函数
module.hot.dispose(fn);
module.hot.removeDisposeHandler(fn);- 每个模块做这些事:
- 有parent和children属性,用于跟踪父子关系
- 给 hot API
- 给两个方法check和apply
- 获取更新 先check再apply。 check就是检查更新并下载更新的module和chunk(发请求获取最新manifest.json); apply会:1)将所有模块标记为invalid;2)每个模块分别检查他自己和父模块是否有accept handler,没有则刷新,有则冒泡到最先遇到的accept handler模块为止;3)dispose和unload每个invalidate模块;4)执行所有accept handler
- 主要逻辑在Runtime,Compiler负责提供更新后的module和chunk列表
Webpack的运行时如何实现?
构建工具通常需要搭配一套Runtime把构建产物跑起来。 这个Runtime可以很简单,比如Rollup、ESBuild,也可以很复杂,比如Webpack。之所以复杂,因为:
- 牵连了很多功能,如Code Splitting、HMR、MF、CSS加载、等
- 需要和编译时搭配使用,比如Webpack的PublicPaht就来自Node环境的配置项
- Webpack还在Runtime引入了插件机制,通过插件挂载的方式支持Code Splitting、HMR、MF等
- 为让代码体积变小,加了很多简写
运行时如何实现?基础流程如下:
- 模块注册和执行
- 定义一个模块Map
- 实现个假的require方法
- require入口模块
- 从入口开始挂载模块并执行
- Chunk的异步加载 Chunk的异步加载基于import()语法做拆分。需要编译时配合:1. 转换import(‘xx’)为用require.ensure()的加载方式,2. 实现chunk的拆分和合并。 require.ensure通过script的方式加载对应的JavaScript文件,并通过jsonp的方式把新增的chunk和module注册进来。
- HMR
+ './a': function (module, exports, require) {
const a = require('./a');
module.exports = { a, b: 1 };
+ }- import('xx')
+ require.ensure(id).then(require.bind(require, id))Webpack的tree shaking为何不太行?
Webpack的实现,是先标记,然后交给Terser或UglifyJS等压缩插件处理,所以换一种压缩器就不行了。 标记分3种:used export,unused harmony export、harmony export。第二种会被shaking掉。
在依赖图中排除没用到的。 rollup与之相反,只打包用到的,故tree shaking效率更高
Vite为啥比Webpack快?
- vite是个bundless打包工具,基于浏览器对ESM的原生支持实现按需加载
- vite启动服务器按需加载,只在请求到模块才会开始编译
- vite使用esbuild预构建依赖(将非ESM包转为ESM形式)并做了缓存,
Webpack和Vite的区别?
- webpack会先打包,然后启动开发服务器,请求服务器时直接给予打包结果。
- 而vite是直接启动开发服务器,请求哪个模块再对该模块进行实时编译。 由于现代浏览器本身就支持ES Module,会自动向依赖的Module发出请求。vite充分利用这一点,将开发环境下的模块文件,就作为浏览器要执行的文件,而不是像webpack那样进行打包合并。 由于vite在启动的时候不需要打包,也就意味着不需要分析模块的依赖、不需要编译,因此启动速度非常快。当浏览器请求某个模块时,再根据需要对模块内容进行编译。这种按需动态编译的方式,极大的缩减了编译时间,项目越复杂、模块越多,vite的优势越明显。
- 在HMR方面,当改动了一个模块后,仅需让浏览器重新请求该模块即可,不像webpack那样需要把该模块的相关依赖模块全部编译一次,效率更高。
- 当需要打包到生产环境时,vite使用传统的rollup进行打包,因此,vite的主要优势在开发阶段。另外,由于vite利用的是ES Module,因此在代码中不可以使用CommonJS
如何做性能优化的?
How we made Vite 4.3 faaaaster 🚀 | sun0day’s blog - lost in code
- 不用resolve库,改为自行实现(更简单、严格、准确,利用缓存)
- 用fs.realpathSync.native替代fs.realpathFileSync,后者慢70倍
- 阻塞式改为非阻塞式,例如:fs.readFileSync改为fs.readFile,这样不会阻塞主线程
- HMR热更增加缓存。
- 并行,比如使用Promise.all替代for循环
- ===相比startsWith和endsWith快20%到60%
- 避免重复创建正则表达式
如何理解依赖预打包?
啥是依赖预打包?就是把依赖提前打包好放在npm包里,然后在package.json中删除响应的依赖,使用时直接引打包后的文件即可。
比如npm包依赖了a,a又依赖了b,那正常的结构就是:
node_modules
a
node_modules
b
index.ts
package.json
经过依赖预打包,变成了:
compiled(node_modules > .vite)
a.js
index.ts
package.json
好处有哪些?
- 锁定依赖,对用户和项目来说更安全,不会出现升级导致的意外情况
- 速度更快,少了很多resolve机制和文件IO,理论上更快
- 让peerDependencies的警告消失
- 可复用1个库的不同版本
缺点有哪些?
- 不能及时享受到三方库的bugfix更新,需要手动升级,通常有滞后
- 依赖版本滞后带来的版本不一致问题
- 潜在的尺寸变大和依赖重复
使用场景:
- 框架和工具可以用,功能原子化的npm包不应该用(没意义)
- node环境可以用,browser环境的包不应该用(预打包后没法tree shaking)
如何实现?
- 基于ncc
- 把源码文件和依赖一起打
如何理解Vite的依赖预构建?
一个项目中存在非常多的模块,并非所有模块都会被预构建,只有裸模块(bare module)会执行依赖预构建。
什么是裸模块?
// 裸模块
import xxx from 'vue';
import xxx from 'vue/xxx';
// 非裸模块
import yyy from './foo';
import yyy from '/foo';简单划分为:名称访问的是裸模块,路径访问的不是裸模块
vite会判断模块的实际路径,是否在node_modules中:
- 实际路径在 node_modules 的模块会被预构建,这是第三方模块
- 实际路径不在 node_modules 的模块,证明该模块是通过文件链接,链接到 node_modules 内的(monorepo 的实现方式),是开发者自己写的代码,不执行预构建
vite先进行依赖扫描,确定哪些模块需要进行依赖预构建。
Vite dev的流程: 创建 Http Server,绑中间件,初始化 Module Graph(依赖图谱),初始化 pluginContainer(插件体系),做 dep optimizier(依赖预编译),就搞定了。然后等着用户访问,url 过来之后做按需 transform(代码主要在这)。dev 还支持 middlewareMode,顾名思义,就是不启动 server,把 vite 作为中间件使用。
build 的流程是读取配置,初始化 pluginContainer,挂载大量插件(20+),组装好 rollup 配置,然后跑 rollup。支持多个进行并行执行,应该是 ssr + csr 的场景。支持 ssr 打包。支持 lib 打包。支持 watch 模式。
optimizer,这是 Vite 快的秘密武器之一。optimizer 的流程是找到入口,通过 esbuild + esbuildScanPlugin 打包入口来记录可能用到的依赖,再跑 esbuild + esbuildDepPlugin 做依赖预编译,入口是拍平的每个依赖。
什么是幽灵依赖?👻
当一个项目使用了一个没有在package.json中定义的包时,就会出现幽灵依赖。
Rollup如何实现的?
实现根据输出输出分为两部分:
// 1. 处理input
const bundle = await rollup(inputOptions);
// 2. output输出
await Promise.all(outputOptions.map(bundle.write));input主体逻辑:
// 生成依赖图谱
this.generateModuleGraph();
// 给模块排序,同时标记statement到模块的引用
this.sortModules();
// tree shaking ?
this.includeStatements();生成依赖图谱通过src/ModuleLoader.ts添加入口模块,然后递归分析和添加依赖。此时会生成大量Module实例,Module通常是文件,每个Module会做transform并返回ast等信息。
output主体逻辑在src/Bundle.ts,代码是await (new Bundle()).generate()。这里会先为dynamic import的模块和入口生成chunks,然后生成物理文件。
插件如何实现? 分为内部和外部。插件是一个包含了一个或多个属性的对象,比如{name, resolveId, load},内部实现是在src/utils/PluginDraver.ts
内部调用方式如:await graph.pluginDriver.hookParallel('buildStart', [inputOptions])
Rollup 提供了 hookFirst、hookFirstSync、hookParallel、hookReduceArg0、hookReduceArg0Sync、hookReduceValue、hookReduceValueSync、hookSeq 共 8 种 Hook 调用机制,有同步和异步,有顺序和并行,等。 Rollup 执行 hook 执行会获取所有包含这个 hook 的插件列表,同时执行 pre 和 post 两种排序方式。
如何实现个简单的Bundler?
- resolve config,解析用户配置,确定入口文件
- build,生成模块依赖图谱
- generate,根据依赖图谱生成代码
build:从入口开始,做load、parse、transform、analyze_deps和resolve,然后把依赖添加到队列中继续跑,直到分析完所有文件为止。
generate:基于build生成的依赖图谱生成最终代码,包含runtime处理、module转code、以及封装成浏览器可以跑的代码,以及代码分割、tree shaking等。最后通过runtime将所有内容拼接起来,针对Node和Browser会有不同runtime
一个基础的Bundler需要包含哪些内容?
源码转义:
- 支持TypeScript
- 支持JavaScript高级语法
- 压缩(包含模块、语句合并)
- Tree Shaking
- 常量标志(比如process.env.NODE_ENV)
- 图片压缩(基于imagemin)
- SVG压缩(基于svgo)
输出格式:
- CommonJS
- ESM
非JavaScript资源:
- CSS(包括CSS Modules、inline引入、CSS Extract、以URL方式引入)
- HTML(包括inline载入脚本,外链载入脚本、Preload图片和字体等、Preload依赖脚本)
- 依赖(产出CSS依赖的三方文件、去重)
- 图片(包括data-url和url两种)
- Service Worker
- Binary(包括Array buffer、url)
- 自定义类型
引入模块:
- CommonJS
- ESM
- node_modules依赖
Hashing
Code Splitting:
- 动态引入
- 单页面多入口文件(共用runtimeChunk)
- 多页面多入口文件
- Chunk共享
- Worker和非Worker共享
- Worker间共享
其他:
- resolve(包含alias、externals、packages.json exports等)
- Source Map
- publicPath
- Targets(modern产物、legacy模式)
- 补丁方案
工程化
如何设计一个插件体系?
Core-Plugin架构组成
- Core:基础功能,提供插件运行的环境,管理插件的注册和卸载(可插拔)以及运行,也即管理插件的生命周期
- Plugin API:插件运行的接口,由Core抽象出来的接口(颗粒度尽可能小)
- Plugin:每个插件都是一个独立的功能模块 好处:
- 提高扩展性
- 减少因功能改变引起的项目迭代,需要扩展的功能可单独发包
- 充分利用开发者/开源的力量,激发更多想法